El fin de IPv4 en los puntos de intercambio: por qué los IXPs avanzan hacia una operación IPv6-only y qué significa para su AS
19/05/2026

Escrito por Antonio Moreiras, Gerente de Proyectos y Desarrollo en NIC.br
La paradoja de Internet que no deja de crecer
IPv4 se acabó. Ya lo sabes. LACNIC, el registro responsable de América Latina y el Caribe, agotó su pool general de direcciones el 19 de agosto de 2020. RIPE NCC, que atiende Europa, hizo lo mismo en noviembre de 2019. Cada nueva dirección IPv4 obtenida hoy viene de devoluciones, recuperaciones o del mercado secundario, donde sondeos de 2026 ubican un bloque /24 (256 direcciones) en alrededor de USD 25 a USD 30 por dirección.
Aun así, Internet no ha dejado de crecer. Aquí en Brasil, donde quien escribe este texto vive, ese crecimiento pasa por los Puntos de Intercambio de Tráfico de IX.br, que es uno de los mayores conjuntos de IXPs existentes y alberga al mayor IXP del mundo en volumen de tráfico y cantidad de redes participantes, el IX.br São Paulo. En marzo de 2026, el conjunto de los IXPs de IX.br alcanzó 50 Tbps de tráfico agregado, con la iniciativa presente en 39 áreas metropolitanas diferentes.
(Acceso libre, no requiere suscripción)
La expansión no es solo brasileña. En América Latina, LAC-IX muestra al menos 117 IXPs diferentes en la región, gestionados por 35 organizaciones distintas. En Argentina, CABASE informa 550 asociados, 28 IXPs coordinados y un tráfico agregado de 4 Tbps. En Chile, PIT Chile ya opera con 151 ASNs y reporta alrededor de 12 Tbps. Este impulso es parte del crecimiento de Internet en la región y recuerda que, a pesar del agotamiento de IPv4, los IXPs siguen siendo motores clave para la expansión, la densificación y la resiliencia de la red.
Sin embargo, hay un problema poco visible en esa expansión. Aunque el tráfico que pasa por un IXP vaya a ser pronto mayoritariamente IPv6, la infraestructura interna, especialmente las sesiones con los route servers, todavía depende de direcciones IPv4 en muchos escenarios. Esas direcciones vienen de pools finitos, gestionados con cuidado creciente por los RIRs. Hay también una segunda motivación, menos obvia pero operacionalmente muy relevante: una LAN de peering IPv6-only permite sacar el ARP del dominio Ethernet del IXP. En lugar de resolver direcciones IPv4 por broadcast Ethernet, el descubrimiento de vecinos pasa a ocurrir por Neighbor Discovery en IPv6, con un modelo más controlable y más adecuado a ambientes compartidos de gran escala. La solución para este problema ya existe, ya está estandarizada y ya está en producción en algunos IXPs. Este artículo explica el problema, la solución y los puntos de atención para los operadores latinoamericanos.
Qué es un IXP y por qué el direccionamiento interno importa
Un IXP es, en esencia, una red Ethernet de gran escala. Cientos de routers de diferentes organizaciones (proveedores de Internet, empresas de contenido, universidades, organismos gubernamentales) se conectan a un switch compartido. A partir de ahí, cada uno establece sesiones BGP con los demás para intercambiar información de enrutamiento y, en consecuencia, encaminar tráfico de forma directa, sin pasar por proveedores intermedios.
La expansión no es solo brasileña. En América Latina, LAC-IX muestra al menos 117 IXPs diferentes en la región, gestionados por 35 organizaciones distintas. En Argentina, CABASE informa 550 asociados, 28 IXPs coordinados y un tráfico agregado de 4 Tbps. En Chile, PIT Chile ya opera con 151 ASNs y reporta alrededor de 12 Tbps. Este impulso es parte del crecimiento de Internet en la región y recuerda que, a pesar del agotamiento de IPv4, los IXPs siguen siendo motores clave para la expansión, la densificación y la resiliencia de la red.
Sin embargo, hay un problema poco visible en esa expansión. Aunque el tráfico que pasa por un IXP vaya a ser pronto mayoritariamente IPv6, la infraestructura interna, especialmente las sesiones con los route servers, todavía depende de direcciones IPv4 en muchos escenarios. Esas direcciones vienen de pools finitos, gestionados con cuidado creciente por los RIRs. Hay también una segunda motivación, menos obvia pero operacionalmente muy relevante: una LAN de peering IPv6-only permite sacar el ARP del dominio Ethernet del IXP. En lugar de resolver direcciones IPv4 por broadcast Ethernet, el descubrimiento de vecinos pasa a ocurrir por Neighbor Discovery en IPv6, con un modelo más controlable y más adecuado a ambientes compartidos de gran escala. La solución para este problema ya existe, ya está estandarizada y ya está en producción en algunos IXPs. Este artículo explica el problema, la solución y los puntos de atención para los operadores latinoamericanos.
Qué es un IXP y por qué el direccionamiento interno importa
Un IXP es, en esencia, una red Ethernet de gran escala. Cientos de routers de diferentes organizaciones (proveedores de Internet, empresas de contenido, universidades, organismos gubernamentales) se conectan a un switch compartido. A partir de ahí, cada uno establece sesiones BGP con los demás para intercambiar información de enrutamiento y, en consecuencia, encaminar tráfico de forma directa, sin pasar por proveedores intermedios.
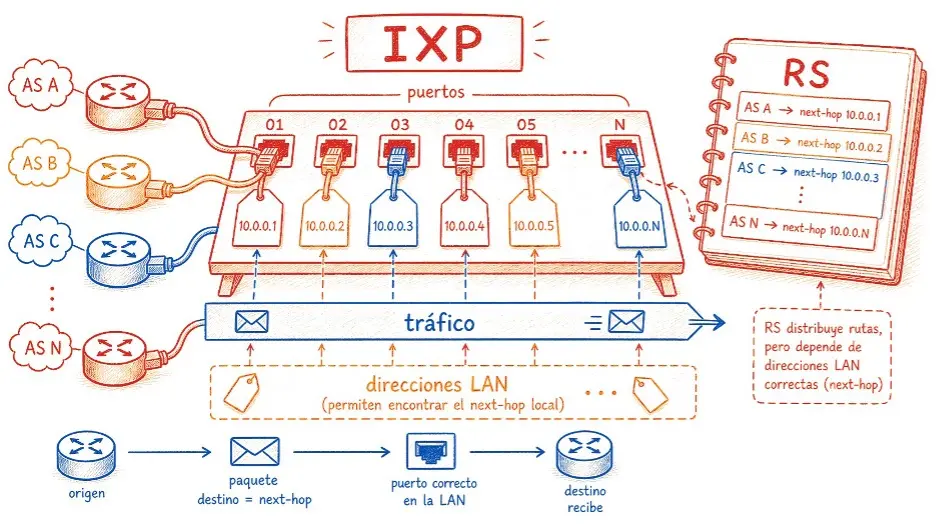
Para facilitar ese proceso, el IXP opera un Route Server (RS). El route server funciona como un agente central de redistribución de rutas: en lugar de que cada participante configure sesiones BGP con todos los demás individualmente, cada uno configura solo una sesión con el RS, que redistribuye las rutas recibidas para todos los demás. En un IXP con 500 miembros, sin route server cada participante necesitaría hasta 499 sesiones bilaterales. Con el RS, basta una. Dos, si hay dos route servers para redundancia.
El problema está justamente en esa sesión con el route server. Para que funcione con rutas IPv4 en el modo tradicional, el protocolo BGP exige que la dirección del siguiente salto (next-hop) también sea una dirección IPv4. Esto significa que cada participante necesita una dirección IPv4 en la interfaz conectada a la LAN de peering, y el IXP necesita un bloque IPv4 para distribuir a todos sus miembros. Incluso en una red que ya opera casi enteramente en IPv6, esa dependencia persiste.
A primera vista, esto parece inevitable: si hay tráfico IPv4, entonces la sesión BGP y el next-hop también tendrían que usar IPv4. Pero no necesitan. La cuestión central es otra: durante muchos años, la forma convencional de operar route servers en IXPs mantuvo una dependencia operacional de IPv4 en la LAN de peering. Y eso importa porque IPv4 dejó de ser un recurso abundante.
¿Cómo pueden seguir surgiendo o expandiéndose IX.br y otros IXPs de América Latina entonces?
Los RIRs y el direccionamiento de IXPs: un recurso protegido, pero finito
Los Registros Regionales de Internet reconocen desde hace mucho tiempo que los IXPs son infraestructuras muy importantes para Internet. Tan importantes, por ejemplo, como la infraestructura de DNS y otras funciones esenciales. Muchas veces estas
infraestructuras, en el ámbito de las reglas definidas por las comunidades en torno a los RIRs, son llamadas “infraestructuras críticas”. Las comunidades en las diferentes regiones crearon políticas especiales para garantizar que direcciones IPv4 para LANs de peering sigan disponibles incluso después del agotamiento del pool general.
El RIPE NCC, por ejemplo, reservó un bloque /15 (131.072 direcciones) exclusivamente para IXPs. La política es rigurosa: el espacio solo puede ser usado para la LAN de peering, y el IXP está obligado a devolverlo si deja de usarlo. Incluso con esa protección, el RIPE NCC proyectaba que ese pool podría agotarse en la segunda mitad de 2029. En 2023, redujo el tamaño estándar de la concesión inicial de /24 a /26, para alargar la vida útil de la reserva.
El LACNIC tiene un enfoque diferente, pero equivalente en intención. La sección 2.3.5 del
Manual de Políticas reserva un bloque /15 para infraestructura crítica, que incluye IXPs,
RIRs y ccTLDs. La Fase 3 del agotamiento regional comenzó el 15 de febrero de 2017; el 19 de agosto de 2020, LACNIC agotó su pool general y pasó a contar solo con recursos recuperados o devueltos, además de la reserva de infraestructura crítica. En consulta al archivo público CRITICAL–INFRA–LATEST el 9 de mayo de 2026, 390 de los 512 bloques /24 que componen ese /15 aún estaban reservados, lo que representa 99.840 direcciones, o cerca de 76% de la reserva.
No hay crisis inmediata. El argumento principal para el cambio técnico no es la urgencia, sino la arquitectura. Cada /24 consumido por un IXP es un bloque que no va para otro uso crítico de la región. La reserva es finita, su consumo es irreversible mientras las redes continúen dependiendo de IPv4 para peering, y esa dependencia ya tiene solución estandarizada.
La raíz técnica del problema: cómo BGP ata nlri y next-hop a la misma familia de direcciones
¿Pero es posible, entonces, usando solo IPv6 en el route server de un IXP, sin tener un pool IPv4 para el IXP, aún así intercambiar información de prefijos IPv4 y encaminar el tráfico normalmente? La respuesta es sí. Y está definida y estandarizada en la RFC 8950.
Para entender la RFC 8950, es necesario entender primero por qué existía la limitación de anunciar prefijos IPv4 con next-hops IPv4. Está en el funcionamiento interno del protocolo BGP, y merece una explicación cuidadosa.
Qué anuncia BGP
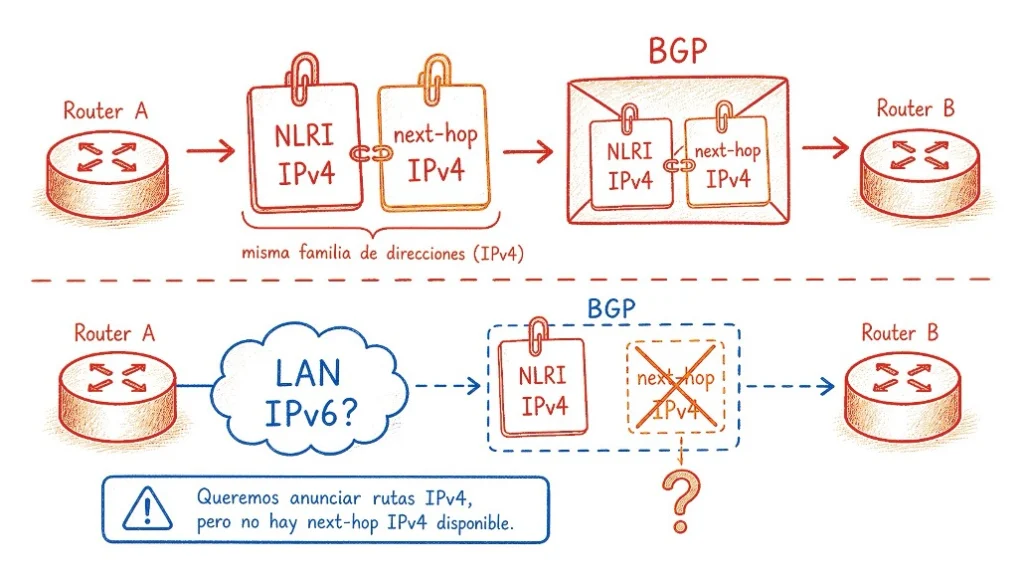
Cuando un router anuncia una ruta vía BGP, envía esencialmente dos datos. El primero es el prefijo alcanzable, llamado NLRI (Network Layer Reachability Information). El segundo es la dirección del siguiente salto para llegar a ese prefijo, el next-hop.
Una buena forma de visualizarlo es pensar en un mapa vial colaborativo. Cada participante anuncia: “la red tal existe y puede alcanzarse por mí”. El NLRI es el destino (“la red 200.1.2.0/24 existe”), y el next-hop es la instrucción de encaminamiento (“para llegar allí, envía los paquetes a la dirección 192.0.2.1, que es mi interfaz aquí en el IXP”). Quien recibe el anuncio usa el next-hop para saber hacia dónde mandar los paquetes.
Esa distinción es importante: el NLRI describe una red que puede estar a decenas de saltos de distancia, pero, en el escenario de una LAN de peering, el next-hop necesita ser una dirección alcanzable en esa red local.
La familia de direcciones y el par AFI/SAFI
El BGP Multiprotocolo (MP-BGP, RFC 4760) extendió el protocolo para soportar múltiples familias de direcciones: IPv4, IPv6, VPNs, MPLS y otras. Para identificar de qué familia se trata cada anuncio, se usa un par de identificadores llamado AFI/SAFI. El AFI (Address Family Identifier) indica la familia principal: 1 para IPv4 y 2 para IPv6. El SAFI (Subsequent Address Family Identifier) indica la subfamilia: 1 para unicast común, 2 para multicast, 4 para labeled unicast (MPLS), 128 para VPN unicast y así sucesivamente.
Cuando un router recibe un mensaje BGP, mira el par AFI/SAFI y sabe de inmediato qué esperar: un anuncio con AFI=1, SAFI=1 es una ruta IPv4 unicast común. Uno con AFI=2, SAFI=1 es una ruta IPv6 unicast.
Con BGP Multiprotocolo ya se puede hacer solo una sesión BGP entre los routers, sobre el protocolo IPv6, y sobre ella anunciar prefijos IPv4, pero solo con next-hops IPv4. Eso no es nuevo, solo no es habitual aún. Pero no es de eso que estamos hablando aquí, vamos un paso más allá. Queremos el NLRI IPv4, es decir, el prefijo IPv4 de destino, pero el next-hop IPv6.
La restricción histórica
El problema está aquí: las especificaciones originales de los pares AFI/SAFI para rutas IPv4 (AFI=1) definían que el campo de next-hop debía contener una dirección IPv4, obligatoriamente. No había previsión de poner una dirección IPv6 en ese campo. La especificación fue escrita en una época en que IPv6 era un proyecto académico, y nadie imaginó que algún día sería necesario anunciar rutas IPv4 usando un next-hop IPv6.
Eso creó una dependencia que parece simple, pero tiene consecuencias profundas: para anunciar rutas IPv4 al route server, un router necesita tener una dirección IPv4 configurada en la interfaz de peering, porque esa dirección será usada como next-hop en los anuncios. Sin IPv4 en la interfaz, no hay next-hop IPv4 válido, y las rutas IPv4 no pueden anunciarse vía RS.
La pregunta natural: ¿pero cómo llega el tráfico?
Aquí surge una pregunta legítima que todo operador hace al primer contacto con el tema. Si un router tiene solo IPv6 en la interfaz del IXP, ¿cómo los paquetes IPv4 llegan hasta él en la práctica?
La respuesta está en separar dos planos que BGP normalmente une: el plano de control (donde las rutas se anuncian y aprenden) y el plano de datos (donde los paquetes realmente circulan).
En el plano de datos, un paquete IPv4 destinado a la red de un participante del IXP no necesita nada especial. Llega al switch del IXP, el switch lo entrega al router correcto usando la dirección MAC de destino en el frame Ethernet, y el router lo procesa normalmente. IPv4 está en el contenido del paquete; el frame Ethernet que lo transporta en la red de capa 2 solo necesita la dirección MAC correcta.
El problema está en el plano de control: ¿cómo el router que va a encaminar el paquete descubre la MAC del router de destino? Con el next-hop IPv4, ese proceso usa ARP. El router envía un broadcast en la LAN de peering preguntando “¿quién tiene la dirección IPv4 192.0.2.5?”, y el dueño responde con su MAC. Si no hay direcciones IPv4 en las interfaces, no hay forma de hacer ese ARP y no hay forma de descubrir la MAC de destino.
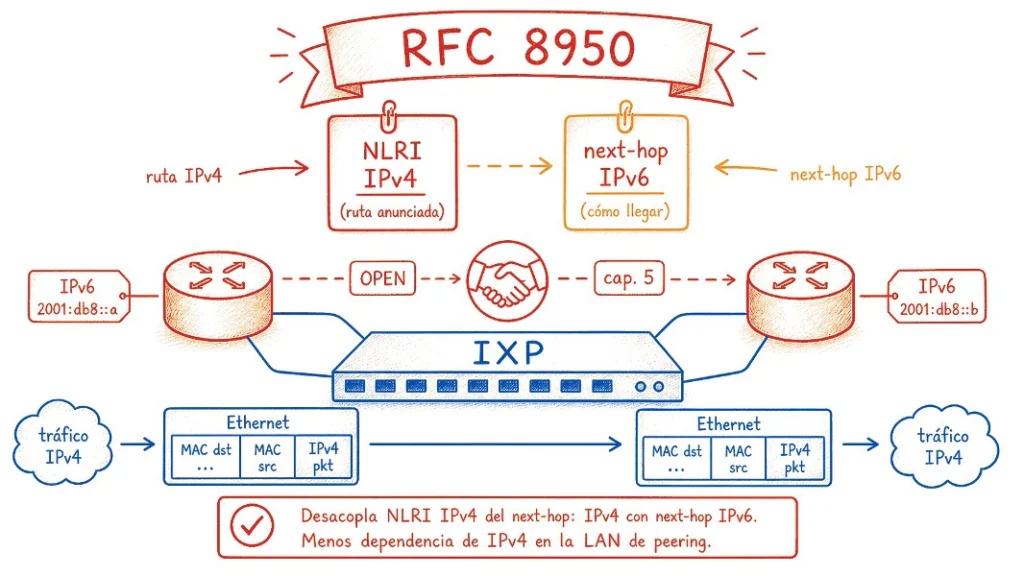
La RFC 8950 resuelve el problema en el plano de control: permite que el router anuncie sus rutas IPv4 usando un next-hop IPv6. Quien recibe el anuncio aprende que “para llegar a la red 200.1.2.0/24, el siguiente salto es la dirección IPv6 2001:db8::1”. Para descubrir la MAC correspondiente a esa dirección IPv6, se usa el Neighbor Discovery (ND), el equivalente IPv6 del ARP. El ND funciona de forma mucho más eficiente: en lugar de broadcast, usa multicast; en lugar de un protocolo separado, es parte integral de IPv6. El router pregunta “¿quién tiene la dirección IPv6 2001:db8::1?” y recibe la MAC de vuelta. A partir de ahí, los paquetes IPv4 se encapsulan en frames Ethernet con destino a la MAC correcta, y circulan normalmente por la LAN de peering.
Para completar la analogía del mapa vial: antes, el mapa decía “para llegar a la red X, ve hasta la estación de servicio amarilla en la esquina” (una dirección IPv4 local). Con la RFC 8950, el mapa pasa a decir “para llegar a la red X, ve hasta la farmacia azul en la avenida principal” (una dirección IPv6). Cualquiera que conozca el barrio puede llegar a la farmacia, la referencia solo se dio de forma distinta, y el tráfico llega al destino de la misma manera. La instrucción cambió de formato, pero la funcionalidad es idéntica.
La solución: RFC 8950 — anunciando rutas Ipv4 con next-hop IPv6
La idea de separar la familia del NLRI de la familia del next-hop no es nueva. La RFC 5549, publicada en 2009, ya proponía exactamente eso. Ya tenía la idea correcta, pero el mercado no estaba listo y la especificación aún tenía aristas en familias BGP importantes para operadoras. La RFC 8950, entonces, no inventó la técnica, sino que consolidó y corrigió el estándar.
La extensión de los pares AFI/SAFI
El primer elemento de la RFC 8950 es la extensión de las definiciones de los pares identificadores de familia. Los pares que describen rutas IPv4 (1/1 para unicast, 1/2 para multicast, 1/4 para labeled unicast, 1/128 para VPN-IPv4 unicast y 1/129 para VPN-IPv4 multicast) pasan a aceptar un next-hop IPv6 en el campo MP_REACH_NLRI del mensaje BGP.
La distinción entre IPv4 e IPv6 en el campo de next-hop se hace por el tamaño del campo, pero hay una diferencia importante entre IPv4 unicast común y VPN-IPv4. Para los pares AFI/SAFI <1/1>, <1/2> y <1/4>, 4 octetos indican next-hop IPv4, mientras 16 o 32 octetos indican next-hop IPv6 (dirección global, opcionalmente seguida de link-local). Para VPN-IPv4 (<1/128> y <1/129>), la RFC 8950 usa 24 o 48 octetos, porque el next-hop se codifica como VPN-IPv6 con un Route Distinguisher de 8 octetos. El receptor verifica el tamaño e interpreta el contenido sin bytes de flag adicionales.
La negociación entre peers: sin sorpresas, sin interrupciones
El segundo elemento es el mecanismo de negociación. Dos routers solo pueden usar la
RFC 8950 si ambos la soportan para un determinado par AFI/SAFI. Para garantizar esto
sin romper sesiones existentes, la RFC define la capacidad BGP de código 5, llamada “Extended Next Hop Encoding”.
Al inicio de cada sesión BGP, los dos routers intercambian mensajes OPEN. En esos mensajes, cada uno anuncia sus capacidades, las extensiones de protocolo que soporta. Con la RFC 8950, un router puede anunciar: “soy capaz de recibir anuncios con NLRI IPv4 unicast (AFI=1, SAFI=1) usando next-hop IPv6 (AFI=2)”. Si el peer remoto también anuncia esa capacidad para el mismo par, ambos pueden usar next-hops IPv6 para esa familia. Si el peer remoto no anuncia nada, la sesión solo debe continuar en el modo convencional, con next-hops IPv4, mientras aún haya IPv4 utilizables en la LAN de peering o algún mecanismo de traducción. En una LAN estrictamente IPv6-only, un peer legado no recibirá rutas IPv4 utilizables sin soporte para RFC 8950 o sin traducción de next-hop.
Ese mecanismo gradual es fundamental para la estrategia de adopción en un IXP real. El route server puede habilitar RFC 8950 y cada miembro migra a su propio ritmo. Los miembros que ya soportan pasan a usar next-hops IPv6. Los que aún no soportan siguen recibiendo next-hops IPv4 mientras el ambiente sea dual-stack o mientras exista una capa de traducción para legados. La transición ocurre peer a peer, sin exigir una ventana de mantenimiento global.
Qué cambia en la red del IXP
Con la RFC 8950 en operación plena, el IXP puede operar la LAN de peering sin asignar direcciones IPv4 públicas a los miembros. Cada miembro configura solo direcciones IPv6 en la interfaz de peering. Las sesiones BGP con el route server usan esas direcciones IPv6. Los anuncios de rutas IPv4 llevan next-hops IPv6. La resolución de MAC usa Neighbor Discovery.
En una LAN realmente IPv6-only, el beneficio no es solo ahorrar direcciones IPv4. Tal vez el beneficio operacional más relevante para el IXP es sacar el ARP de la LAN de peering. El ARP se basa en broadcast: cada consulta se entrega a todos los participantes de ese dominio Ethernet, incluso cuando solo uno de ellos puede responder. En IXPs grandes, esto crea ruido permanente en el plano de control de la capa 2 y aumenta la superficie para problemas como ARP storms, respuestas indebidas, spoofing y necesidad de filtrados específicos.
Con la RFC 8950, la resolución del siguiente salto pasa a depender de Neighbor Discovery sobre IPv6. El ND también exige control operacional, y no debe tratarse como automáticamente seguro, pero usa multicast en lugar de broadcast y permite una política más predecible: el tráfico de descubrimiento queda asociado al direccionamiento IPv6 de la LAN de peering, con menor exposición innecesaria a todos los participantes. Así, la transición a IPv6-only mejora no solo la gestión de direcciones, sino también la higiene operacional de la propia red Ethernet del IXP. En escenarios de transición con peers legados, sin embargo, ARP aún puede existir de forma controlada, normalmente mediante proxy y filtrado por el IXP.
| Escenario | Sesión BGP | NLRI IPv4 | Next-hop para IPv4 | Resolución de MAC |
| Tradicional | IPv4 o dual-stack | Sí | IPv4 | ARP |
| RFC 8950 puro | IPv6 | Sí | IPv6 | Neighbor Discovery |
| Brownfield con legado | IPv6 para quien soporta; IPv4 o traducción para legados | Sí | IPv6 internamente; IPv4 sintético para legados | ND y ARP/ND proxy |
Lo que no cambia: el tráfico de los usuarios
Vale dejar absolutamente claro lo que la RFC 8950 no altera: el tráfico IPv4 de los usuarios finales sigue fluyendo normalmente. La RFC 8950 opera exclusivamente en el plano de control del BGP, en el intercambio de información de enrutamiento entre los routers participantes. Un paquete de datos que sale de una red de contenido y llega a un usuario final atraviesa la LAN del IXP exactamente como antes. El switch del IXP lo reenvía por la dirección MAC de destino en el frame Ethernet. El router de destino lo recibe y lo encamina hacia su red. Ninguna de esas operaciones es afectada por la RFC 8950.
El cambio está entre bastidores: en la forma en que los routers aprenden dónde están las redes de los demás, no en la forma en que los paquetes de los usuarios llegan al destino.
Tres años construyendo el ecosistema (2023–2026)
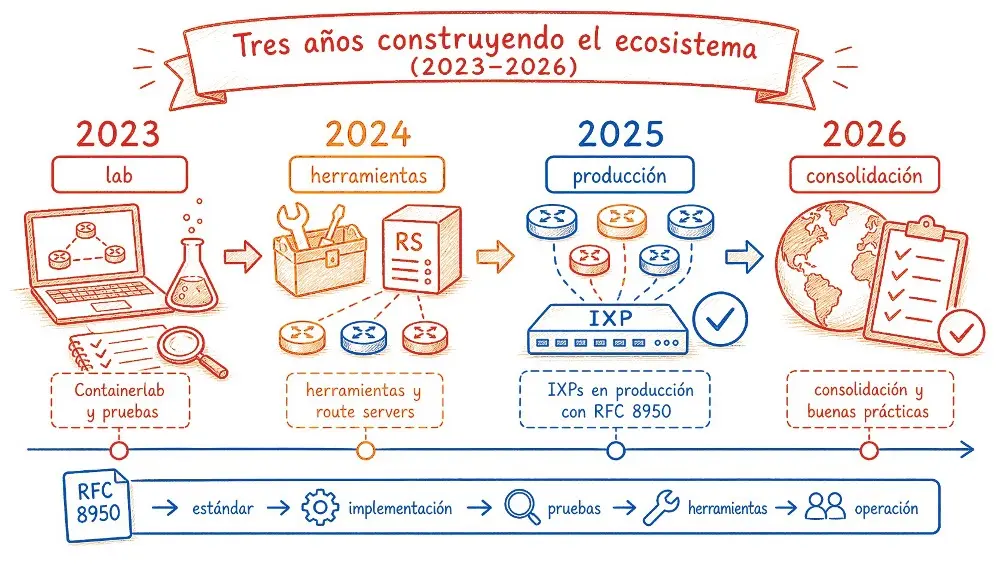
Un estándar bien escrito no mueve una industria por sí solo. Hace falta que fabricantes implementen, que operadores prueben en condiciones reales, que herramientas como route servers y looking glasses se adapten, y que la comunidad produzca documentación práctica. Ese trabajo se hizo de forma organizada y deliberada entre 2023 y 2026, por un grupo de trabajo informal vinculado a Euro-IX.
En 2023, el grupo formalizó su charter, definió objetivos y montó un ambiente de laboratorio virtual usando Containerlab, una herramienta que permite simular topologías de red completas en software. Las primeras pruebas por fabricante se distribuyeron entre los miembros. Arista EOS y Juniper Junos funcionaron. Nokia SR-OS necesitó investigación adicional. ExaBGP no tenía documentación para el recurso. Se aceptó un pull request con configuración para FRR en el repositorio. Se inició una tabla de compatibilidad por fabricante. En noviembre, un taller abierto reveló la complejidad del escenario brownfield y puso en agenda la necesidad de soportar la coexistencia entre peers con y sin RFC 8950.
En 2024, los avances fueron más rápidos. ARouteServer incorporó soporte para RFC 8950 como recurso oficial. IXP Manager manifestó interés en hacer lo mismo. Un ambiente de peering experimental con RFC 8950 se puso en operación real en un IXP europeo, con sesiones reales de BGP. Nokia SR-OS pasó a funcionar en el laboratorio virtual. El impacto de RFC 8950 en los filtros de higiene del route server se evaluó y confirmó como manejable. Meta presentó, en el plenario del RIPE 88, el trabajo de eliminación de direccionamiento IPv4 de infraestructura en su red de borde, usando IPv6 next-hop para anuncios IPv4 en partes de la arquitectura.
En 2025, el primer IXP exclusivamente RFC 8950 del mundo entró en operación, en Finlandia, en el TREX Turku. Otros IXPs europeos activaron route servers RFC 8950 en producción, incluyendo BCIX y NIX.CZ/NIX.SK. MikroTik RouterOS 7.20 implementó el recurso. Alice-LG pasó a soportar BIRD multi-channel BGP y RFC 8950. Se publicó una matriz de interoperabilidad multifabricante, con resultados de pruebas entre múltiples fabricantes y sistemas operativos. IXP Manager publicó plantillas oficiales de configuración.
En 2026, el grupo de trabajo cerró las reuniones regulares y migró el trabajo restante hacia discusiones de route server, declarando que la mayor parte de los objetivos había sido cumplida. Al mismo tiempo, redes de contenido comenzaron a tratar la técnica como requisito operacional: DeepL, por ejemplo, declara en su PeeringDB que configura nuevas sesiones BGP solo sobre IPv6 para ambas familias de direcciones, usando BGP Extended Next Hop/RFC 8950.
El estado actual: quién ya lo hace y qué muestran los números
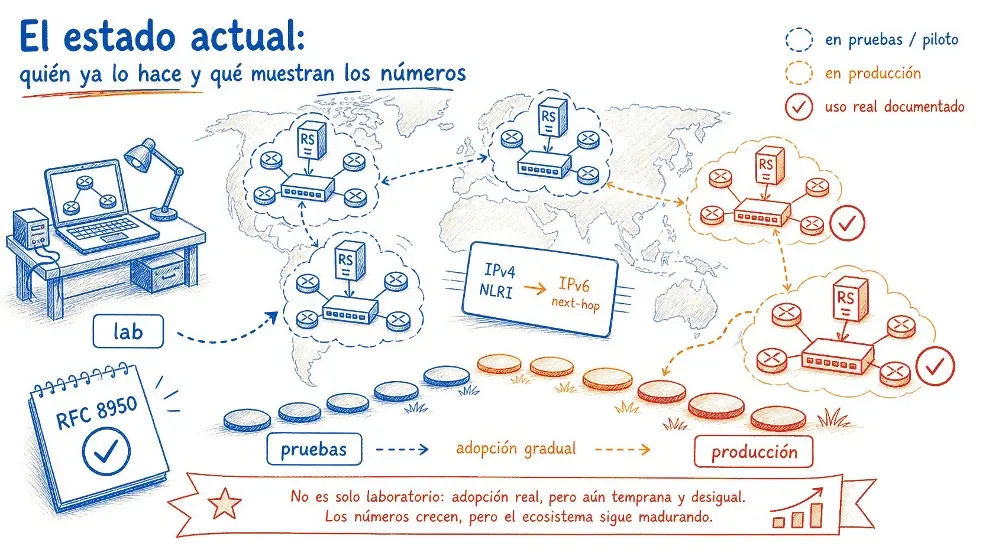
El estado actual es de adopción todavía inicial, pero ya real. En materiales públicos del grupo Euro-IX, los ejemplos documentados incluyen al TREX Turku como RFC 8950-only, TREX Tampere en route servers de prueba y BCIX, NIX.CZ y NIX.SK con route servers RFC
8950 en producción. En BCIX (Berlín), una presentación operacional registraba 7 ASNs con RFC 8950 habilitado. El punto importante no es el número absoluto, que cambia rápidamente, sino el hecho de que la técnica salió del laboratorio y ya entró en operación en IXPs reales.
Del lado de los fabricantes, el soporte existe en varios sistemas operativos de red, pero el estado es desigual. La tabla siguiente resume la información del repositorio Euro-IX consultado el 9 de mayo de 2026; en producción, vale validar siempre la versión exacta, la familia de direcciones usada y si hay soporte solo en RIB o también en FIB.
Fabricante/proyec
| to | Sistema | Estado observado |
| Arista | EOS | Desde 4.22.1F; algún soporte ya en 4.17 |
| Cisco | IOS XE | No soportado para el caso general de IXP; hay soporte a IPv6 next-hop para rutas VPN desde 17.8.1 |
| Cisco | IOS XR | Desde 7.3.3 |
| Cisco | NX-OS | Soportado, pero no probado por el grupo |
| CZNIC | BIRD 2/3 + Linux | BIRD 2 desde 2.0.8; BIRD 3 desde 3.0.0; requiere Linux 5.2 para FIB |
| FRR | FRR + Linux | Desde 7.0.0; 9.1.3 recomendado; requiere Linux 5.2 |
Fabricante/proyec
| to | Sistema | Estado observado |
| Huawei | VRP | Parcial en 8.240; probado en NE8000 V800R024, todavía sin FIB en el relevamiento |
| Juniper | Junos | Desde 21.2; hay reportes de soporte anterior y de incompatibilidades en versiones antiguas |
| MikroTik | RouterOS | Desde 7.20, introducido en el ciclo beta 7.20beta5 |
| Nokia | SR-OS | Desde 20.2.R1 en el README de Euro-IX |
| Nokia | SR Linux | Desde 20.06; probado por el grupo en 22.6.4 |
| OpenBGPD | OpenBGPD | 8.8, solo RIB |
| OSRG | GoBGP | Soportado hace varios años, sin FIB probado |
| Vyatta | VyOS | Desde 1.2.2; 1.4.3 o superior recomendado |
El problema del legado: no todos hablan RFC 8950
Un IXP de gran tamaño, como IX.br y otros puntos de intercambio importantes de la región, tiene cientos de miembros, con equipos de diferentes fabricantes y diferentes versiones de software. No es razonable, ni operacionalmente viable, exigir que todos migren al mismo tiempo. La transición necesita ser gradual. Eso exige que, durante un período que puede ser largo, peers con y sin soporte para RFC 8950 convivan en la misma LAN de peering.
Ese es el escenario brownfield, y es probablemente el mayor desafío técnico de la adopción de RFC 8950 en IXPs de gran escala.
El problema central de la coexistencia
Si el route server anuncia rutas con next-hop IPv6 a un peer que no soporta RFC 8950, ese peer no puede usar las rutas recibidas. No sabe qué hacer con un next-hop IPv6 en una ruta IPv4. Puede incluso establecer la sesión BGP, pero el tráfico no fluye.
El camino más elegante es hacer que el propio route server realice la traducción automáticamente, según el tipo de peer. Eso es lo que el Internet-Draft de Matějka y Wagner propone.
El draft IETF de traducción de next-hop
Maria Matějka, desarrolladora de BIRD en CZ.NIC, y Daniel Wagner, de DE-CIX, publicaron el Internet-Draft individual “Route Server Next Hop Translation”. La versión -01, del 27 de febrero de 2026, está en discusión pública en el contexto de GROW/IETF y debe leerse como trabajo en curso, no como estándar aprobado.
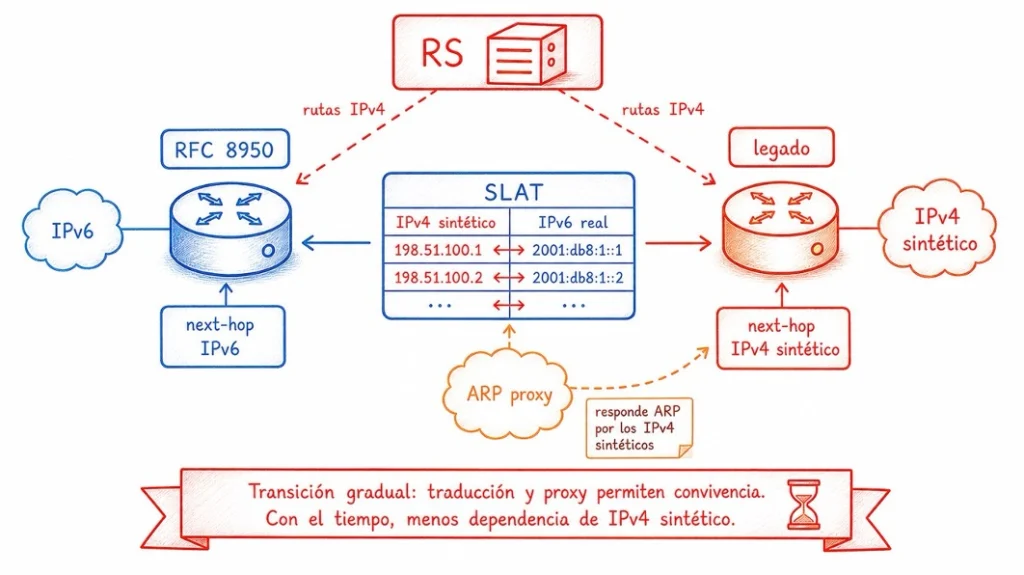
La propuesta introduce el concepto de SLAT (Specific Local Address Table, Tabla de Direcciones Locales Específicas).
La SLAT: una tabla de traducción por miembro
La SLAT es una tabla mantenida por el IXP con una entrada por miembro. Cada entrada contiene la dirección MAC del equipo del miembro, su dirección IPv6 link-local, su dirección IPv6 global y una o más direcciones IPv4 sintéticas, extraídas de bloques reservados para uso estrictamente interno a la interconexión del IXP.
Una forma simple de entender la SLAT es pensarla como una tabla de traducción. El route server recibe anuncios de rutas IPv4, guarda internamente el next-hop en IPv6 y, cuando necesita hablar con un participante legado, entrega la ruta con un next-hop IPv4 sintético que ese participante puede instalar. La traducción es automática y determinística, basada en la tabla mantenida por el IXP.
El draft distingue tres tipos de participantes del IXP:
- El Legacy Speaker es el participante que no soporta RFC 8950. Solo entiende next-hops IPv4 y necesita tener una dirección IPv4 sintética en la SLAT para poder interactuar con el sistema.
- El Supporting Speaker soporta RFC 8950 pero también acepta next-hops IPv4. Puede funcionar de ambos modos, lo que lo hace útil durante períodos de transición.
- El Unnumbered Speaker soporta solo RFC 8950 y no tiene ninguna dirección IPv4 en la interfaz del IXP. Es el participante completamente independiente de IPv4 en la LAN de peering.
Cómo usa el route server la SLAT
El mecanismo funciona así. Cuando cualquier participante anuncia una ruta IPv4 al route server, el RS convierte inmediatamente el next-hop a la dirección IPv6 del anunciante, consultando la SLAT. A partir de ese momento, internamente, todas las rutas IPv4 tienen next-hops IPv6.
Al distribuir una ruta a un Unnumbered Speaker, el RS la envía con el next-hop IPv6. Ninguna conversión adicional necesaria.
Al distribuir una ruta a un Legacy Speaker, el RS consulta la SLAT y reemplaza el next-hop IPv6 del anunciante por la dirección IPv4 sintética correspondiente, en la columna específica de ese Legacy Speaker. El Legacy Speaker recibe la ruta con un next-hop IPv4 local y la instala en su tabla de enrutamiento normalmente.
El problema del ARP y la solución del proxy
El Legacy Speaker, al intentar encaminar tráfico hacia ese next-hop IPv4 sintético, emitirá una consulta ARP: “¿quién tiene la dirección 192.0.2.X?”. Para responder a esa consulta, el IXP necesita tener un ARP proxy configurado. El proxy intercepta consultas ARP de la LAN de peering, consulta la SLAT para descubrir qué MAC corresponde a qué IPv4 sintética, y responde en nombre del propietario de esa dirección. El Legacy Speaker recibe la respuesta, aprende la MAC y encamina el frame Ethernet hacia el destino correcto. Por la misma razón, el draft también trata de ND proxy y de filtrado para evitar que ARP y ND sean simplemente reenviados entre clientes.
Es un proceso transparente para el Legacy Speaker: hace un ARP normal y recibe una respuesta normal. Por debajo de la superficie, hay una indirección gestionada por el IXP.
Ese detalle es importante: la traducción no cambia el paquete IPv4 del usuario. Cambia solo la forma en que el router legado descubre la MAC asociada al next-hop presentado por el route server.
El espacio de interconexión del IXP
Las direcciones IPv4 sintéticas necesitan venir de algún lugar. El draft propone que IANA asigne un /8 del rango 240/4 como bloque IPv4 de uso especial, llamado “IXP Interconnection Space”, específicamente para esa finalidad. Usar un bloque estandarizado trae dos ventajas: los miembros de diferentes IXPs que utilicen el mismo bloque comparten la misma convención, reduciendo el tamaño de las tablas SLAT; y evita conflictos con direcciones enrutables en Internet pública, ya que esas direcciones sintéticas nunca deben anunciarse fuera del IXP. Como se trata de un Internet-Draft, esa asignación aún es una propuesta.
La limitación importante: Peerings bilaterales
El mecanismo descrito resuelve la traducción en el contexto de las sesiones vía route server. Peerings bilaterales directos, en los que dos miembros establecen sesión BGP directamente entre sí sin pasar por el RS, no se resuelven automáticamente por el route server. Para esos casos, ambos peers necesitarían soportar RFC 8950 entre sí, mantener direcciones IPv4 en la interfaz específicamente para esas sesiones, o implementar la traducción por su cuenta con base en información publicada por el IXP.
En IXPs de gran escala, los peerings bilaterales pueden ser numerosos. Esa limitación es real y debe considerarse en la planificación. El draft la reconoce explícitamente y trata el caso bilateral como responsabilidad de los propios participantes, aunque sugiere que la SLAT se ponga a disposición pública para facilitar traducciones fuera del route server.
¿Serán el IX.br, la Cabase, el PIT Chile y otros ixps de América Latina pronto IPv6-only?
IX.br aún no tiene planes concretos para la adopción de RFC 8950, aunque ya hay conversaciones internas en marcha, y el autor de este texto no dispone de información sobre cómo están las discusiones en el ámbito de LAC-IX y de los IXPs en otros países de la región. Aun así, la dirección de Internet es clara. IPv6 avanza en adopción global de forma consistente. La escasez de IPv4 se profundiza gradualmente. Y la comunidad técnica internacional demostró, con tres años de trabajo documentado y resultados en producción, que RFC 8950 es viable a escala real.
Defiendo la adopción de RFC 8950 en IX.br y en los IXPs de América Latina tan pronto como sea posible, pero es importante que eso ocurra con cuidado. “Tan pronto como sea posible” no quiere decir que tenga que hacerse ahora. Antes de cualquier implementación masiva, todos deben estar atentos a los mecanismos de transición, especialmente para los casos con legados y para los fabricantes cuya implementación aún no está madura. Es importante traer este asunto al ámbito del LAC-IX.
Lo que los IXPs, ISPs y operadores de AS latinoamericanos pueden hacer ahora es prepararse con anticipación. Sin prisa. Sin alarma.
Para los ISPs y otras redes, el primer paso es entender el nuevo estándar, familiarizarse con el concepto. Este artículo tiene la pretensión de ayudar en ello. El segundo paso es el inventario: ¿qué routers de borde tienen soporte para RFC 8950? ¿En qué versión de sistema operativo se introdujo el soporte? La tabla de compatibilidad anterior es un buen punto de partida. El paso siguiente es experimentar, es el laboratorio. Montar un ambiente de simulación con Containerlab es gratuito y accesible. Es posible simular una LAN de peering con un route server RFC 8950 y algunos routers virtuales en pocas horas. Ver cómo se negocia la capacidad Extended Next Hop en el OPEN, cómo aparece el next-hop IPv6 en las tablas de enrutamiento, cómo se comporta el traceroute sin IPv4 en la interfaz, todo eso en laboratorio, sin riesgo para la red de producción. El repositorio EURO–IX/RFC8950-IXP en GitHub tiene ejemplos listos para Containerlab y guías de configuración por fabricante.
Finalmente, un paso importante es seguir las discusiones en el IETF, en particular el draft de Matějka y Wagner, en la lista de GROW, que está en fase de discusión pública. Participar o al menos leer los comentarios de la comunidad técnica internacional es una forma eficiente de seguir cómo el problema del legado se está abordando antes de que llegue al ambiente latinoamericano.
Conclusión
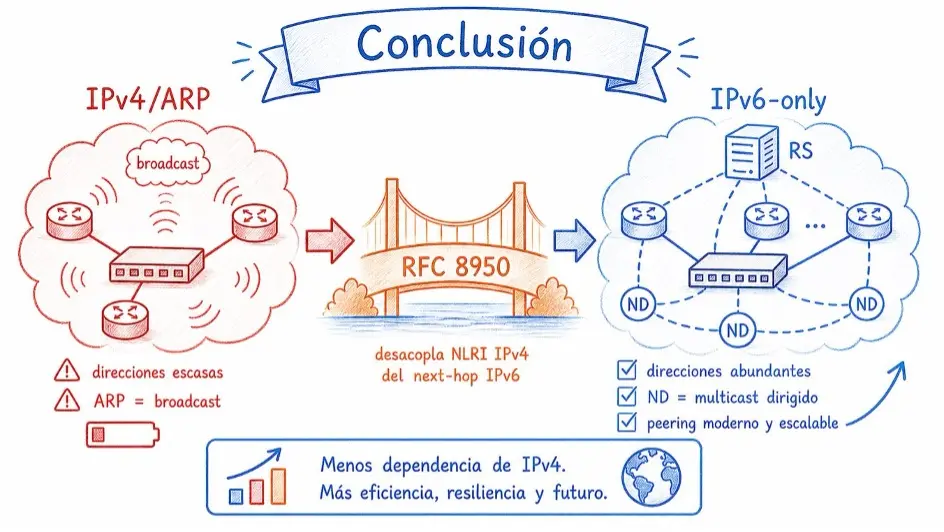
La transición de los IXPs hacia operación IPv6-only en las sesiones de route server no es una ruptura repentina. Es una evolución técnica que ya está en curso, con estándar consolidado, herramientas maduras y resultados comprobados en producción en IXPs reales.
RFC 8950 resuelve una limitación técnica real del protocolo BGP: desacopla la familia de direcciones del NLRI de la familia del next-hop, permite negociación incremental peer a peer y elimina la dependencia de direcciones IPv4 en la LAN de peering en los escenarios en que todos los participantes relevantes soportan la técnica. El resultado no es solo ahorro de direcciones IPv4: es también una LAN de peering más limpia, con menos dependencia de broadcast ARP y con resolución de vecindad concentrada en el plano IPv6. El draft complementario de Matějka y Wagner aborda el escenario de coexistencia con peers legados, haciendo viable una transición gradual en IXPs de gran escala, aunque aún sea trabajo en curso.
En América Latina, el momento es de estudio y preparación. La presión operacional aún no es urgente, IX.br y la mayoría de los IXPs de la región no tienen planes inmediatos de cambio, y algunos fabricantes ampliamente usados en la región aún tienen pendientes de implementación. Pero Internet camina hacia IPv6, y quien comience a entender y probar RFC 8950 hoy llegará al momento de la transición con mucha más tranquilidad que quien espere para aprender cuando la necesidad sea inmediata.
El camino está mapeado, la documentación está disponible, y Containerlab ya permite probar la idea sin riesgo para la red de producción. Monte el laboratorio, vea cómo funciona y comparta su experiencia.
Referencias
- RFC Editor. RFC 8950: ADVERTISING IPV4 NETWORK LAYER REACHABILITY INFORMATION (NLRI) WITH AN IPV6 NEXT HOP, noviembre de 2020.
- IETF Datatracker. DRAFT–MARENAMAT–GROW–ROUTE–SERVER–NH–TRANSLATION-01: ROUTE SERVER NEXT HOP TRANSLATION, 27 de febrero de 2026.
- Euro-IX. REPOSITORIO RFC8950-IXP, incluyendo README, ejemplos y presentaciones. ● Euro-IX mailing list. CONCLUDING THE RFC8950-IXP WORKING GROUP, marzo de 2026.
- CGI.br/NIC.br. IX.BR BATE RÉCORD DE 50 TBIT/S DE TRÁFICO INTERNET AGREGADO, 20 de marzo de 2026
- LACNIC. FASES DE AGOTAMIENTO DE IPV4 y MANUAL DE POLÍTICAS, SECCIÓN 2.3.5.
- LACNIC. CRITICAL–INFRA–LATEST, archivo público de estadísticas de la reserva de infraestructura crítica.
- RIPE NCC. POLICY PROPOSAL 2023-01: REDUCING IXP IPV4 ASSIGNMENT DEFAULT SIZE TO A /26, aceptada e implementada el 14 de septiembre de 2023.
- RIPE 88. REMOVING IPV4 INFRASTRUCTURE ADDRESSING FROM META‘S EDGE NETWORK, mayo de 2024.
- LAC-IX. SITIO INSTITUCIONAL Y MAPA REGIONAL DE IXPS.
- CABASE. ATLAS DE LA RED NACIONAL DE IXP 2025.
- Internet Society Pulse. PIT CHILE SANTIAGO, IXP Tracker.
- IPv4.Center. IPV4 MARKET REPORT 2026, marzo de 2026.
- PeeringDB. AS60550 – DEEPL SE.
Las opiniones expresadas por los autores de este blog son propias y no necesariamente reflejan las opiniones de LACNIC.