O fim do IPv4 nos pontos de troca de tráfego: por que os IXPs caminham para ser IPv6-only e o que isso significa para seu AS
19 de maio de 2026
Por Antonio M. Moreiras, Projects and development manager @ NIC.br | Driving Internet development in Brazil.
O paradoxo da Internet que não para de crescer
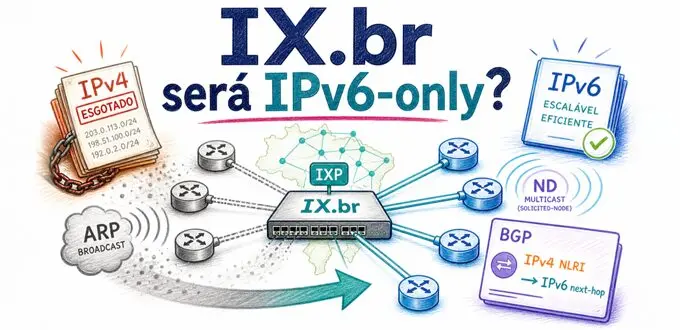
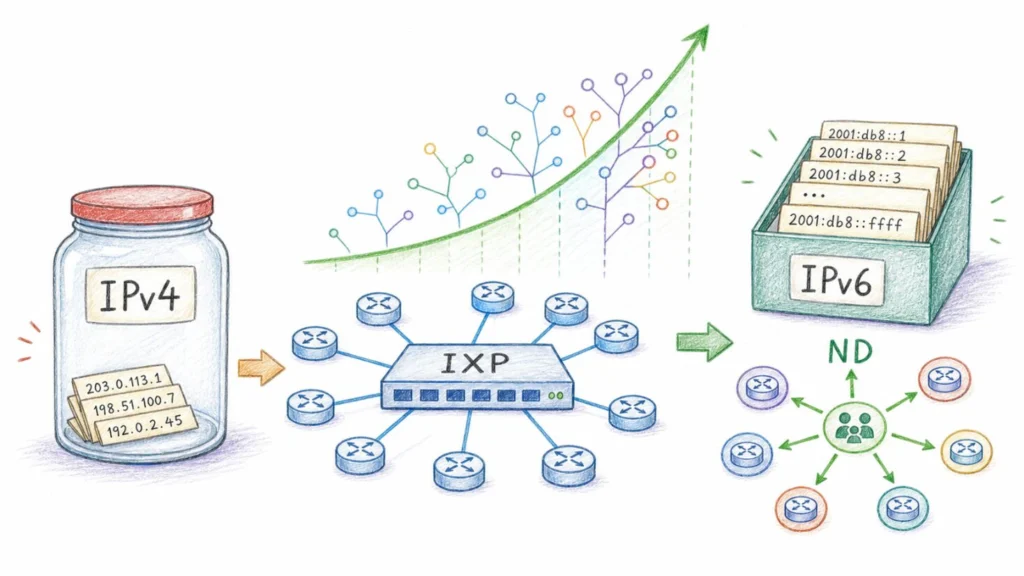
O IPv4 acabou. Você já sabe disso. O LACNIC, registro responsável pela América Latina e Caribe, esgotou seu pool geral de endereços em 19 de agosto de 2020. O RIPE NCC, que atende a Europa, fez o mesmo em novembro de 2019. Cada novo endereço IPv4 obtido hoje vem de devoluções, recuperações ou do mercado secundário, onde levantamentos de 2026 colocam um bloco /24 (256 endereços) em torno de USD 25 a USD 30 por endereço.
Apesar disso, a Internet não parou de crescer. Aqui no Brasil, esse crescimento passa pelos Pontos de Troca de Tráfego do IX.br, que é um dos maiores conjuntos de IXPs existentes e abriga o maior IXP do mundo em volume de tráfego e quantidade de redes participantes, o IX.br São Paulo. Em março de 2026, o conjunto dos PTTs do IX.br atingiu 50 Tbit/s de tráfego agregado, com a iniciativa presente em 39 diferentes áreas metropolitanas.
(Acesso livre, não requer assinatura)
Há, porém, um problema pouco visível nessa expansão. Mesmo que o tráfego que passa por um IXP venha a ser em breve majoritariamente IPv6, a infraestrutura interna, especialmente as sessões com o route server, ainda depende de endereços IPv4 em muitos cenários. Esses endereços vêm de pools finitos, gerenciados com cuidado crescente pelos RIRs. Há também uma segunda motivação, menos óbvia mas operacionalmente muito relevante: uma peering LAN IPv6-only permite retirar o ARP do domínio Ethernet do IXP. Em vez de resolver endereços IPv4 por broadcast Ethernet, a descoberta de vizinhos passa a ocorrer por Neighbor Discovery em IPv6, com um modelo mais controlável e mais adequado a ambientes compartilhados de grande escala. A solução para esse problema já existe, já está padronizada e já está em produção em alguns IXPs. Este artigo explica o problema, a solução e os pontos de atenção para os operadores brasileiros.
O que é um IXP e por que o endereçamento interno importa
O que é um IXP e por que o endereçamento interno importa
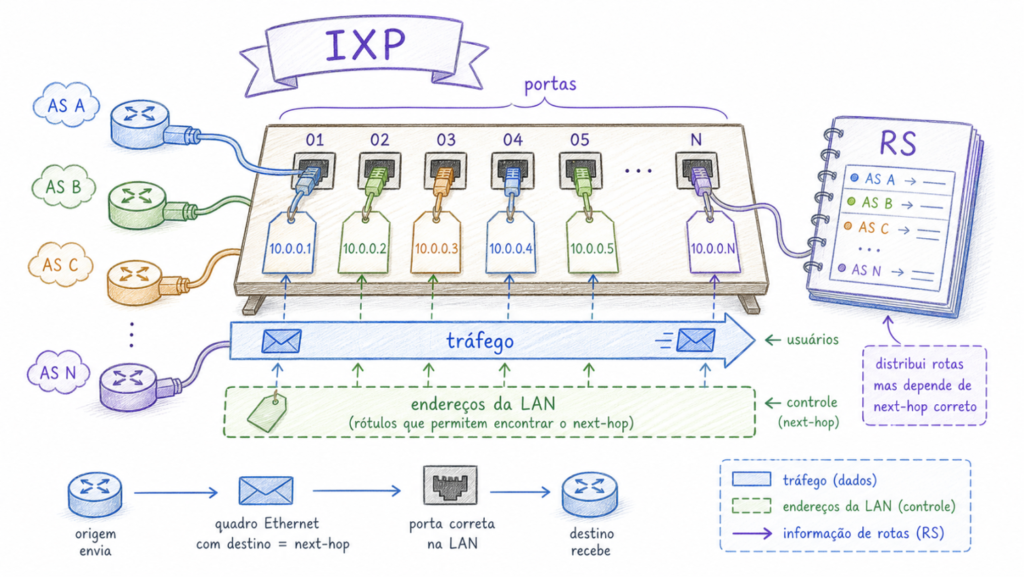
Um IXP é, na essência, uma rede Ethernet de grande porte. Centenas de roteadores de diferentes organizações (provedores de Internet, empresas de conteúdo, universidades, órgãos governamentais) conectam-se a um switch compartilhado. A partir daí, cada um estabelece sessões BGP com os demais para trocar informações de roteamento e, consequentemente, encaminhar tráfego de forma direta, sem passar por provedores intermediários.
Há, porém, um problema pouco visível nessa expansão. Mesmo que o tráfego que passa por um IXP venha a ser em breve majoritariamente IPv6, a infraestrutura interna, especialmente as sessões com o route server, ainda depende de endereços IPv4 em muitos cenários. Esses endereços vêm de pools finitos, gerenciados com cuidado crescente pelos RIRs. Há também uma segunda motivação, menos óbvia mas operacionalmente muito relevante: uma peering LAN IPv6-only permite retirar o ARP do domínio Ethernet do IXP. Em vez de resolver endereços IPv4 por broadcast Ethernet, a descoberta de vizinhos passa a ocorrer por Neighbor Discovery em IPv6, com um modelo mais controlável e mais adequado a ambientes compartilhados de grande escala. A solução para esse problema já existe, já está padronizada e já está em produção em alguns IXPs. Este artigo explica o problema, a solução e os pontos de atenção para os operadores brasileiros.
O que é um IXP e por que o endereçamento interno importa
O que é um IXP e por que o endereçamento interno importa
Um IXP é, na essência, uma rede Ethernet de grande porte. Centenas de roteadores de diferentes organizações (provedores de Internet, empresas de conteúdo, universidades, órgãos governamentais) conectam-se a um switch compartilhado. A partir daí, cada um estabelece sessões BGP com os demais para trocar informações de roteamento e, consequentemente, encaminhar tráfego de forma direta, sem passar por provedores intermediários.
Para facilitar esse processo, o IXP opera um Route Server (RS). O route server funciona como um agente central de redistribuição de rotas: em vez de cada participante configurar sessões BGP com todos os outros individualmente, cada um configura apenas uma sessão com o RS, que redistribui as rotas recebidas para todos os demais. Em um IXP com 500 membros, sem route server cada participante precisaria de até 499 sessões bilaterais. Com o RS, basta uma. Duas, se houver dois route servers para redundância.
O problema está justamente nessa sessão com o route server. Para que ela funcione com rotas IPv4 no modo tradicional, o protocolo BGP exige que o endereço do próximo salto (o next-hop) também seja um endereço IPv4. Isso significa que cada participante precisa de um endereço IPv4 na interface conectada à LAN de peering, e o IXP precisa de um bloco IPv4 para distribuir a todos os seus membros. Mesmo numa rede que já opera quase inteiramente em IPv6, essa dependência persiste.
À primeira vista, isso parece inevitável: se há tráfego IPv4, então a sessão BGP e o next-hop também teriam que usar IPv4. Certo? Não, não precisam, e é isso que veremos em detalhe ao longo deste artigo.
Mas podemos fazer ainda mais uma pergunta importante: durante muitos anos, a forma convencional de operar route servers em IXPs manteve uma dependência operacional de IPv4 na LAN de peering. Isso ainda é verdade. E isso importa porque IPv4 deixou de ser um recurso abundante. Se os provedores não têm mais IPv4, como, então, o IX.br e outros PTTs continuam surgindo ou se expandindo?
Os RIRs e o endereçamento de IXPs: um recurso protegido, mas finito
Os RIRs e o endereçamento de IXPs: um recurso protegido, mas finito
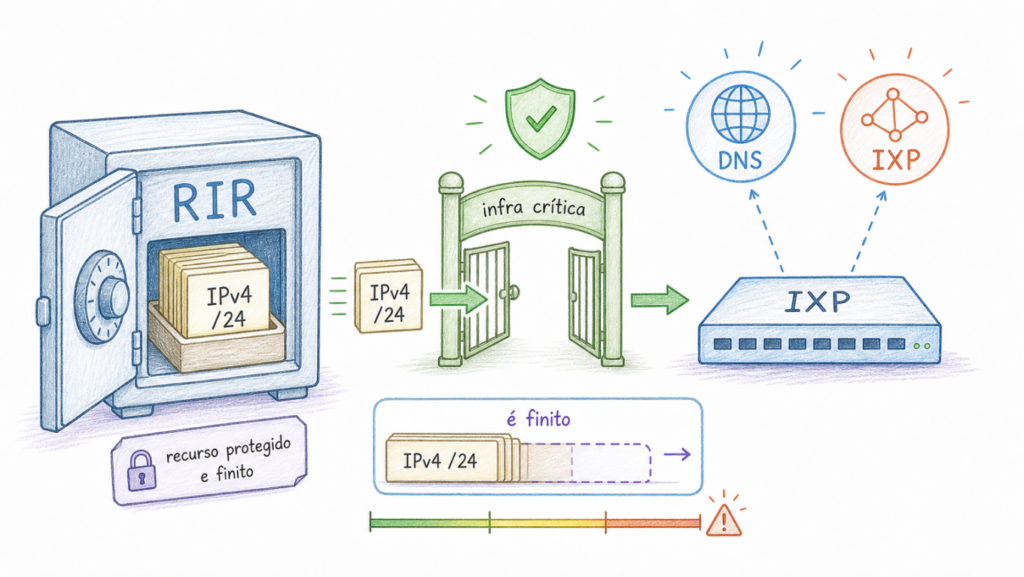
Os Registros Regionais de Internet reconhecem há muito tempo que IXPs são infraestruturas muito importantes para a Internet. Tão importantes, por exemplo, quanto a infraestrutura de DNS e outras funções essenciais. Muitas vezes essas infraestruturas, no escopo das regras definidas pelas comunidades em torno dos RIRs, são chamadas de “infraestruturas críticas”. As comunidades nas diferentes regiões criaram políticas especiais para garantir que endereços IPv4 para peering LANs continuem disponíveis mesmo após o esgotamento do pool geral.
O RIPE NCC, por exemplo, reservou um bloco /15 (131.072 endereços) exclusivamente para IXPs. A política é rigorosa: o espaço só pode ser usado para a LAN de peering, e o IXP é obrigado a devolvê-lo se parar de usá-lo. Mesmo com essa proteção, o RIPE NCC projetava que esse pool poderia se esgotar na segunda metade de 2029. Em 2023, reduziu o tamanho padrão da concessão inicial de /24 para /26, para esticar a vida útil da reserva.
O LACNIC, aqui em nossa região, tem uma abordagem diferente, mas equivalente em intenção. A seção 2.3.5 do Manual de Políticas reserva um bloco /15 para infraestrutura crítica, que inclui IXPs, RIRs e ccTLDs. A Fase 3 do esgotamento regional começou em 15 de fevereiro de 2017; em 19 de agosto de 2020, o LACNIC esgotou seu pool geral e passou a contar apenas com recursos recuperados ou devolvidos, além da reserva de infraestrutura crítica. Em consulta ao arquivo público critical-infra-latest em 9 de maio de 2026, 390 dos 512 blocos /24 que compõem esse /15 ainda estavam reservados, o que representa 99.840 endereços, ou cerca de 76% da reserva.
Não há crise imediata. O argumento principal para a mudança técnica não é a urgência, mas a arquitetura. Cada /24 consumido por um IXP é um bloco que não vai para outro uso crítico da região. A reserva é finita, seu consumo é irreversível enquanto as redes continuarem dependendo de IPv4 para peering, e essa dependência já tem solução padronizada.
A raiz técnica do problema: como o BGP amarra NLRI e next-hop à mesma família de endereços
A raiz técnica do problema: como o BGP amarra NLRI e next-hop à mesma família de endereços
Mas é possível, então, usando apenas IPv6 no route server de um IXP, sem ter um pool IPv4 para o PTT, ainda assim trocar informações de prefixos IPv4 e encaminhar o tráfego normalmente? A resposta é sim. E é na RFC 8950 que está definida e padronizada a forma para se fazer isso.
Para entender a RFC 8950, é necessário entender primeiro por que existia a limitação de anunciar prefixos IPv4 com next-hops IPv4. Ela está no funcionamento interno do protocolo BGP, e merece uma explicação cuidadosa.
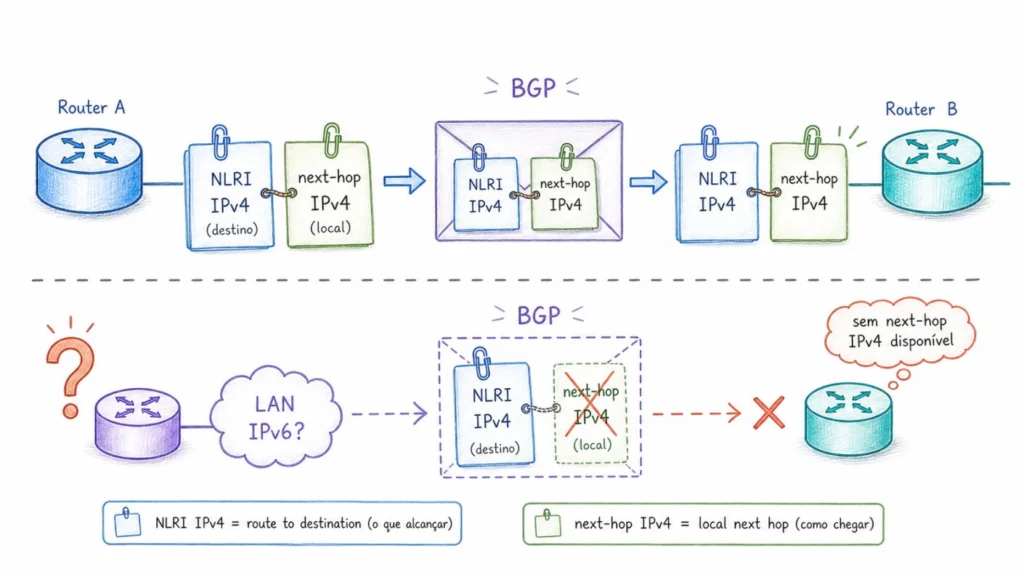
O que o BGP anuncia
Quando um roteador anuncia uma rota via BGP, ele envia essencialmente duas informações. A primeira é o prefixo alcançável, chamado de NLRI (Network Layer Reachability Information). A segunda é o endereço do próximo salto para chegar até aquele prefixo, o next-hop.
Uma boa forma de visualizar isso é pensar em um mapa rodoviário colaborativo. Cada participante anuncia: “a rede tal existe e pode ser alcançada por mim”. O NLRI é o destino (“rede 200.1.2.0/24 existe”), e o next-hop é a instrução de encaminhamento (“para chegar lá, envie os pacotes para o endereço 192.0.2.1, que é minha interface aqui no IXP”). Quem recebe o anúncio usa o next-hop para saber para onde mandar os pacotes.
Essa distinção é importante: o NLRI descreve uma rede que pode estar a dezenas de saltos de distância, mas, no cenário de uma LAN de peering, o next-hop precisa ser um endereço alcançável nessa rede local.
A família de endereços e o par AFI/SAFI
O BGP Multiprotocolo (MP-BGP, RFC 4760) estendeu o protocolo para suportar múltiplas famílias de endereços: IPv4, IPv6, VPNs, MPLS e outras. Para identificar de qual família se trata cada anúncio, usa-se um par de identificadores chamado AFI/SAFI. O AFI (Address Family Identifier) indica a família principal: 1 para IPv4 e 2 para IPv6. O SAFI (Subsequent Address Family Identifier) indica a subfamília: 1 para unicast comum, 2 para multicast, 4 para labeled unicast (MPLS), 128 para VPN e assim por diante.
Quando um roteador recebe uma mensagem BGP, ele olha para o par AFI/SAFI e sabe imediatamente o que esperar: um anúncio com AFI=1, SAFI=1 é uma rota IPv4 unicast comum. Um com AFI=2, SAFI=1 é uma rota IPv6 unicast.
Com o BGP Multiprotocolo você já consegue fazer apenas uma sessão BGP entre os roteadores, sobre o protocolo IPv6, e sobre ela anunciar prefixos IPv4, mas até então, apenas com next-hops IPv4. Isso não é novo, só não é usual. Mas não é disso que estamos falando aqui, estamos indo um passo além. Queremos anunciar uma rota sobre uma sessão BGP que foi fechada via protocolo IPv6, tendo: (i) o NLRI IPv4, ou seja, com um prefixo IPv4 como destino, mas com (ii) o next-hop IPv6.
A restrição histórica
O problema está aqui: as especificações originais dos pares AFI/SAFI para rotas IPv4 (AFI=1) definiam que o campo de next-hop deveria conter um endereço IPv4, obrigatoriamente. Não havia previsão de colocar um endereço IPv6 nesse campo. A especificação foi escrita numa época em que IPv6 era projeto acadêmico, e ninguém imaginou que um dia seria necessário anunciar rotas IPv4 usando um next-hop IPv6.
Isso criou uma dependência que parece simples, mas tem consequências profundas: para anunciar rotas IPv4 ao route server, um roteador precisa ter um endereço IPv4 configurado na interface de peering, porque esse endereço vai ser usado como next-hop nos anúncios. Sem IPv4 na interface, não há next-hop IPv4 válido, e as rotas IPv4 não podem ser anunciadas via RS.
Então, sem a RFC 8950, não adiantava nada padronizar as sessões no route server com IPv6, anunciando os prefixos IPv4 com BGP Multiprotocolo sobre elas, se o next-hop ainda tinha que ser IPv4. De qualquer jeito haveria necessidade de termos endereçamento IPv4 na rede de peering.
A pergunta natural: mas como o tráfego chega?
Aqui surge uma pergunta legítima que todo operador faz ao primeiro contato com o tema. Se um roteador tem apenas IPv6 na interface do IXP, como os pacotes IPv4 chegam até ele na prática?
A resposta está em separar dois planos que o BGP normalmente une: o plano de controle (onde as rotas são anunciadas e aprendidas) e o plano de dados (onde os pacotes realmente trafegam).
No plano de dados, um pacote IPv4 destinado à rede de um participante do IXP não precisa de nada especial. Ele chega ao switch do IXP, o switch o entrega ao roteador correto usando o endereço MAC de destino no frame Ethernet, e o roteador o processa normalmente. O IPv4 está no conteúdo do pacote; o frame Ethernet que o carrega na rede de camada 2 só precisa do endereço MAC correto.
O problema está no plano de controle: como o roteador que vai encaminhar o pacote descobre o MAC do roteador de destino? Com o next-hop IPv4, esse processo usa ARP. O roteador envia um broadcast na LAN de peering perguntando “quem tem o endereço IPv4 192.0.2.5?”, e o dono responde com seu MAC. Se não há endereços IPv4 nas interfaces, não há como fazer esse ARP e não há como descobrir o MAC de destino.
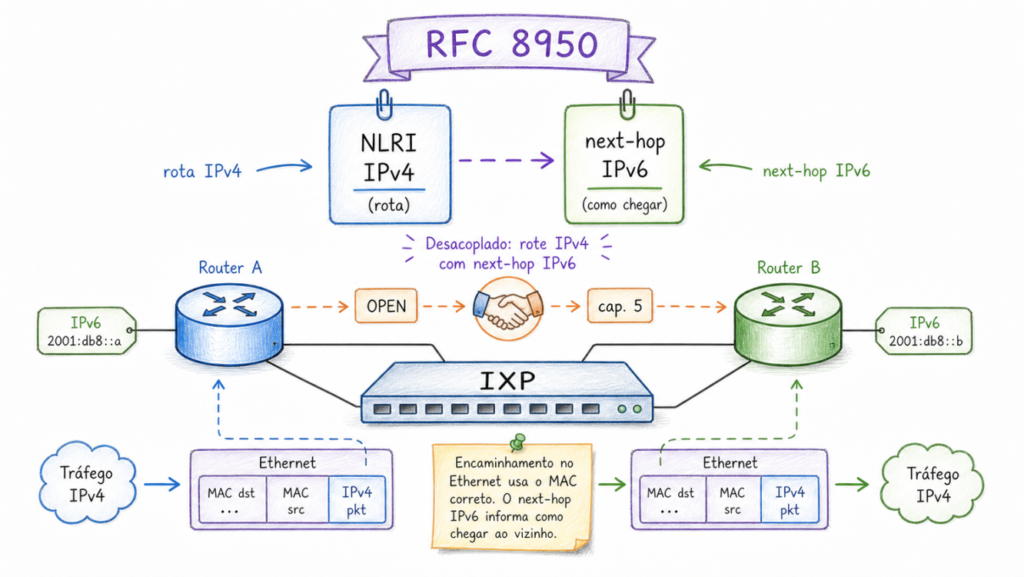
A RFC 8950 resolve o problema no plano de controle: permite que o roteador anuncie suas rotas IPv4 usando um next-hop IPv6. Quem recebe o anúncio aprende que “para chegar à rede 200.1.2.0/24, o próximo salto é o endereço IPv6 2001:db8::1”. Para descobrir o MAC correspondente a esse endereço IPv6, usa-se o Neighbor Discovery (ND), o equivalente IPv6 do ARP. O ND funciona de forma muito mais eficiente: em vez de broadcast, usa multicast; em vez de um protocolo separado, é parte integrante do IPv6. O roteador pergunta “quem tem o endereço IPv6 2001:db8::1?” e recebe o MAC de volta. A partir daí, os pacotes IPv4 são encapsulados em frames Ethernet com destino ao MAC correto, e trafegam normalmente pela LAN de peering.
Para completar a analogia do mapa rodoviário: antes, o mapa dizia “para chegar à rede X, vá até o posto de gasolina amarelo na esquina” (um endereço IPv4 local). Com a RFC 8950, o mapa passa a dizer “para chegar à rede X, vá até a farmácia azul na avenida principal” (um endereço IPv6). Qualquer um que conheça o bairro consegue chegar à farmácia, a referência apenas foi dada de forma diferente, e o tráfego chega ao destino da mesma forma. A instrução mudou de formato, mas a funcionalidade é idêntica.
A solução: RFC 8950 — anunciando rotas IPv4 com next-hop IPv6
A solução: RFC 8950 — anunciando rotas IPv4 com next-hop IPv6
A ideia de separar a família do NLRI da família do next-hop não é nova. A RFC 5549, publicada em 2009, já propunha exatamente isso. Ela já tinha a ideia certa, mas o mercado não estava pronto e a especificação ainda tinha arestas em famílias BGP importantes para operadoras. A RFC 8950, então, não inventou a técnica, mas consolidou e corrigiu o padrão.
A extensão dos pares AFI/SAFI
O primeiro elemento da RFC 8950 é a extensão das definições dos pares identificadores de família. Os pares que descrevem rotas IPv4 (1/1 para unicast, 1/2 para multicast, 1/4 para labeled unicast, 1/128 para VPN-IPv4 unicast e 1/129 para VPN-IPv4 multicast) passam a aceitar um next-hop IPv6 no campo MP_REACH_NLRI da mensagem BGP.
A distinção entre IPv4 e IPv6 no campo de next-hop é feita pelo tamanho do campo, mas há uma diferença importante entre IPv4 unicast comum e VPN-IPv4. Para os pares AFI/SAFI <1/1>, <1/2> e <1/4>, 4 octetos indicam next-hop IPv4, enquanto 16 ou 32 octetos indicam next-hop IPv6 (endereço global, opcionalmente seguido de link-local). Para VPN-IPv4 (<1/128> e <1/129>), a RFC 8950 usa 24 ou 48 octetos, porque o next-hop é codificado como VPN-IPv6 com um Route Distinguisher de 8 octetos. O receptor verifica o tamanho e interpreta o conteúdo sem bytes de flag adicionais.
A negociação entre peers: sem surpresas, sem interrupções
O segundo elemento é o mecanismo de negociação. Dois roteadores só podem usar a RFC 8950 se ambos a suportarem para determinado par AFI/SAFI. Para garantir isso sem quebrar sessões existentes, a RFC define a capacidade BGP de código 5, chamada de “Extended Next Hop Encoding”.
No início de cada sessão BGP, os dois roteadores trocam mensagens OPEN. Nessas mensagens, cada um anuncia suas capacidades, as extensões de protocolo que suporta. Com a RFC 8950, um roteador pode anunciar: “sou capaz de receber anúncios com NLRI IPv4 unicast (AFI=1, SAFI=1) usando next-hop IPv6 (AFI=2)”. Se o peer remoto também anunciar essa capacidade para o mesmo par, ambos podem usar next-hops IPv6 para aquela família. Se o peer remoto não anunciar, a sessão só deve continuar no modo convencional, com next-hops IPv4, se ainda houver IPv4 utilizável na LAN de peering ou algum mecanismo de tradução. Em uma LAN estritamente IPv6-only, um peer legado não receberá rotas IPv4 utilizáveis sem suporte à RFC 8950 ou sem tradução de next-hop.
Esse mecanismo gradual é fundamental para a estratégia de adoção em um IXP real. O route server pode habilitar RFC 8950 e cada membro migra no seu próprio ritmo. Os membros que já suportam passam a usar next-hops IPv6. Os que ainda não suportam continuam recebendo next-hops IPv4 enquanto o ambiente ainda for dual-stack ou enquanto existir uma camada de tradução para legados. A transição acontece peer a peer, sem exigir uma janela de manutenção global.
O que muda na rede do IXP
Com a RFC 8950 em operação plena, o IXP pode operar a LAN de peering sem alocar endereços IPv4 públicos para os membros. Cada membro configura apenas endereços IPv6 na interface de peering. As sessões BGP com o route server usam esses endereços IPv6. Os anúncios de rotas IPv4 carregam next-hops IPv6. A resolução de MAC usa Neighbor Discovery.
Em uma LAN realmente IPv6-only, o ganho não é apenas economizar endereços IPv4. Talvez o ganho operacional mais relevante para o IXP seja remover o ARP da peering LAN. O ARP é baseado em broadcast: cada consulta é entregue a todos os participantes daquele domínio Ethernet, mesmo quando apenas um deles pode responder. Em IXPs grandes, isso cria ruído permanente no plano de controle da camada 2 e aumenta a superfície para problemas como ARP storms, respostas indevidas, spoofing e necessidade de filtragens específicas.
Com a RFC 8950, a resolução do próximo salto passa a depender de Neighbor Discovery sobre IPv6. O ND também exige controle operacional, e não deve ser tratado como automaticamente seguro, mas usa multicast em vez de broadcast e permite uma política mais previsível: o tráfego de descoberta fica associado ao endereçamento IPv6 da LAN de peering, com menor exposição desnecessária a todos os participantes. Assim, a transição para IPv6-only melhora não apenas a gestão de endereços, mas também a higiene operacional da própria rede Ethernet do IXP. Em cenários de transição com peers legados, porém, ARP ainda pode existir de forma controlada, normalmente por meio de proxy e filtragem pelo IXP.

Cenários de operação e resolução de MAC
O que não muda: o tráfego dos usuários
Vale deixar absolutamente claro o que a RFC 8950 não altera: o tráfego IPv4 dos usuários finais continua fluindo normalmente. A RFC 8950 opera exclusivamente no plano de controle do BGP, na troca de informações de roteamento entre os roteadores participantes. Um pacote de dados saindo de um servidor em São Paulo e chegando a um usuário em Recife atravessa o IX.br exatamente como antes. O switch do IXP o encaminha pelo endereço MAC de destino no frame Ethernet. O roteador de destino o recebe e o encaminha para sua rede. Nenhuma dessas operações é afetada pela RFC 8950.
A mudança está nos bastidores: na forma como os roteadores aprendem onde estão as redes uns dos outros, não na forma como os pacotes dos usuários chegam ao destino.
Três anos construindo o ecossistema (2023–2026)
Três anos construindo o ecossistema (2023–2026)
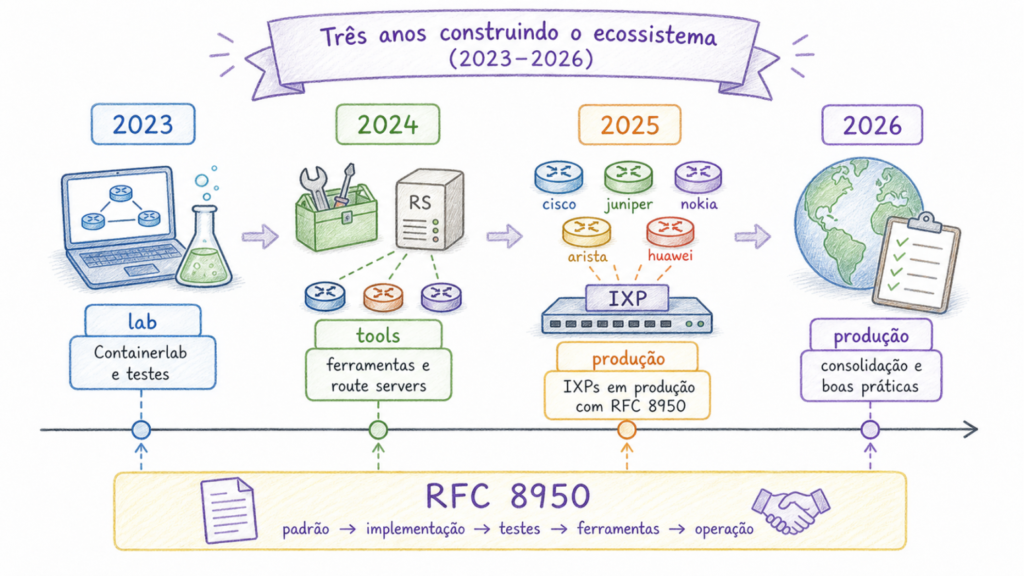
Um padrão bem escrito não move uma indústria sozinho. É preciso que fabricantes implementem, que operadores testem em condições reais, que ferramentas como route servers e looking glasses se adaptem, e que a comunidade produza documentação prática. Esse trabalho foi feito de forma organizada e deliberada entre 2023 e 2026, por um grupo de trabalho informal ligado ao Euro-IX.
Em 2023, o grupo formalizou seu charter, definiu objetivos e montou um ambiente de laboratório virtual usando Containerlab, uma ferramenta que permite simular topologias de rede completas em software. Os primeiros testes por fabricante foram distribuídos entre os membros. Arista EOS e Juniper Junos funcionaram. Nokia SR-OS precisou de investigação adicional. ExaBGP não tinha documentação para o recurso. Um pull request com configuração para FRR foi aceito no repositório. Uma tabela de compatibilidade por fabricante foi iniciada. Em novembro, um workshop aberto revelou a complexidade do cenário brownfield e colocou em pauta a necessidade de suportar a coexistência entre peers com e sem RFC 8950.
Em 2024, os avanços foram mais rápidos. O ARouteServer incorporou suporte à RFC 8950 como recurso oficial. O IXP Manager sinalizou interesse em fazer o mesmo. Um ambiente de peering experimental com RFC 8950 foi colocado em operação real em um IXP europeu, com sessões reais de BGP. A Nokia SR-OS passou a funcionar no laboratório virtual. O impacto da RFC 8950 nos filtros de higiene do route server foi avaliado e confirmado como gerenciável. A Meta apresentou, no plenário do RIPE 88, o trabalho de remoção de endereçamento IPv4 de infraestrutura em sua rede de borda, usando IPv6 next-hop para anúncios IPv4 em partes da arquitetura.
Em 2025, o primeiro IXP exclusivamente RFC 8950 do mundo entrou em operação, na Finlândia, no TREX Turku. Outros IXPs europeus ativaram route servers RFC 8950 em produção, incluindo BCIX e NIX.CZ/NIX.SK. O MikroTik RouterOS 7.20 implementou o recurso. O Alice-LG passou a suportar BIRD multi-channel BGP e RFC 8950. Uma matriz de interoperabilidade multifabricante foi publicada, com resultados de testes entre múltiplos fabricantes e sistemas operacionais. O IXP Manager publicou templates oficiais de configuração.
Em 2026, o grupo de trabalho encerrou as reuniões regulares e migrou o trabalho remanescente para discussões de route server, declarando que a maior parte dos objetivos havia sido cumprida. Ao mesmo tempo, redes de conteúdo começaram a tratar a técnica como requisito operacional: a DeepL, por exemplo, declara em sua PeeringDB que configura novas sessões BGP apenas sobre IPv6 para ambas as famílias de endereços, usando BGP Extended Next Hop/RFC 8950.
O estado atual: quem já faz e o que os números mostram
O estado atual: quem já faz e o que os números mostram
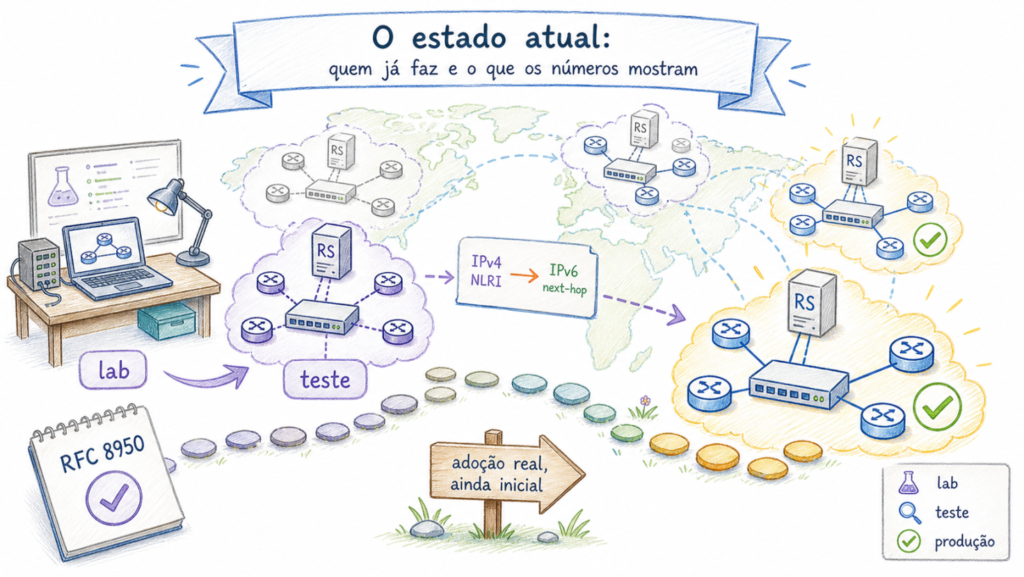
O estado atual é de adoção ainda inicial, mas já real. Em materiais públicos do grupo Euro-IX, os exemplos documentados incluem o TREX Turku como RFC 8950-only, TREX Tampere em route servers de teste e BCIX, NIX.CZ e NIX.SK com route servers RFC 8950 em produção. No BCIX (Berlim), uma apresentação operacional registrava 7 ASNs com RFC 8950 habilitado. O ponto importante não é o número absoluto, que muda rapidamente, mas o fato de que a técnica saiu do laboratório e já entrou em operação em IXPs reais.
Do lado dos fabricantes, o suporte existe em vários sistemas operacionais de rede, mas o estado é desigual. A tabela abaixo resume o levantamento do repositório Euro-IX consultado em 9 de maio de 2026; em produção, vale validar sempre a versão exata, a família de endereço usada e se há suporte apenas em RIB ou também em FIB.
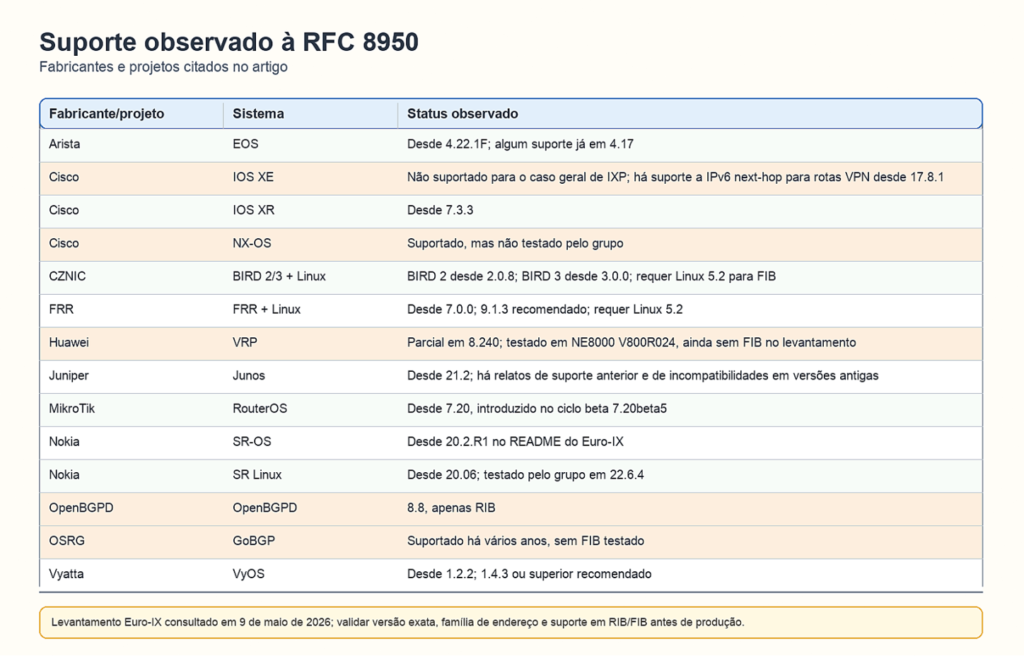
Suporte dos fabricantes.
O problema do legado: nem todos falam RFC 8950
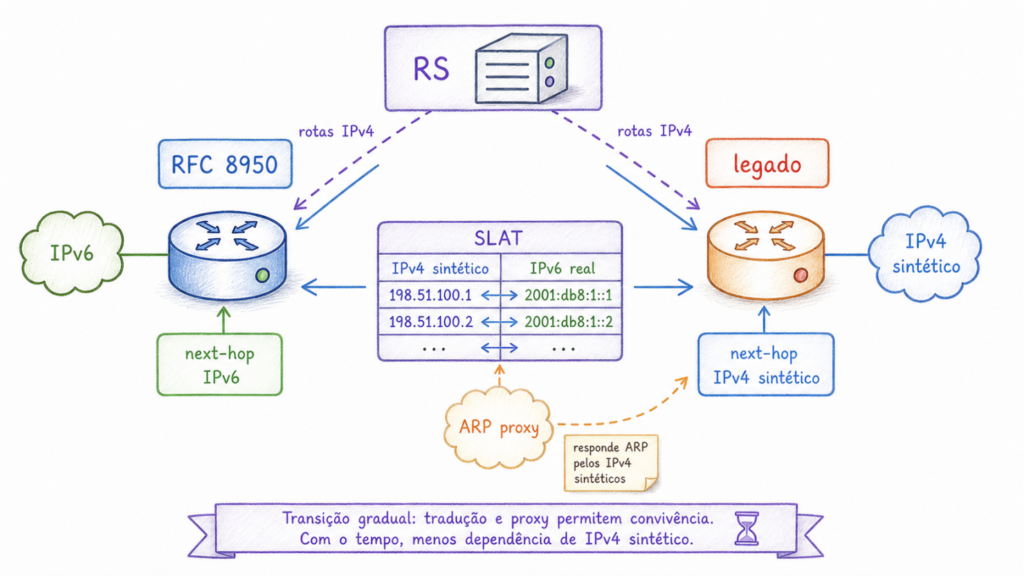
O problema do legado: nem todos falam RFC 8950
Um IXP como o IX.br tem centenas de membros, com equipamentos de diferentes fabricantes e diferentes versões de software. Não é razoável, nem operacionalmente viável, exigir que todos migrem ao mesmo tempo. A transição precisa ser gradual. Isso exige que, durante um período que pode ser longo, peers com e sem suporte à RFC 8950 coexistam na mesma LAN de peering.
Esse é o cenário brownfield, e é provavelmente o maior desafio técnico da adoção da RFC 8950 em IXPs de grande porte.
O problema central da coexistência
Se o route server anuncia rotas com next-hop IPv6 para um peer que não suporta RFC 8950, esse peer não consegue usar as rotas recebidas. Ele não sabe o que fazer com um next-hop IPv6 numa rota IPv4. Pode até estabelecer a sessão BGP, mas o tráfego não flui.
O caminho mais elegante é fazer o próprio route server realizar a tradução automaticamente, conforme o tipo de peer. É isso que o Internet-Draft de Matějka e Wagner propõe.
O draft IETF de tradução de next-hop
Maria Matějka, desenvolvedora do BIRD no CZ.NIC, e Daniel Wagner, do DE-CIX, publicaram o Internet-Draft individual “Route Server Next Hop Translation”. A versão -01, de 27 de fevereiro de 2026, está em discussão pública no contexto do GROW/IETF e deve ser lida como trabalho em andamento, não como padrão aprovado.
A proposta introduz o conceito de SLAT (Specific Local Address Table, Tabela de Endereços Locais Específicos).
A SLAT: uma tabela de tradução por membro
A SLAT é uma tabela mantida pelo IXP com uma entrada por membro. Cada entrada contém o endereço MAC do equipamento do membro, seu endereço IPv6 link-local, seu endereço IPv6 global e um ou mais endereços IPv4 sintéticos, retirados de blocos reservados para uso estritamente interno à interconexão do IXP.
Uma forma simples de entender a SLAT é pensar nela como uma tabela de tradução. O route server recebe anúncios de rotas IPv4, guarda internamente o next-hop em IPv6 e, quando precisa falar com um participante legado, entrega a rota com um next-hop IPv4 sintético que aquele participante consegue instalar. A tradução é automática e determinística, baseada na tabela mantida pelo IXP.
O draft distingue três tipos de participantes do IXP:
- O Legacy Speaker é o participante que não suporta RFC 8950. Ele só entende next-hops IPv4 e precisa ter um endereço IPv4 sintético na SLAT para poder interagir com o sistema.
- O Supporting Speaker suporta RFC 8950 mas também aceita next-hops IPv4. Pode funcionar dos dois modos, o que o torna útil durante períodos de transição.
- O Unnumbered Speaker suporta apenas RFC 8950 e não tem endereço IPv4 nenhum na interface do IXP. É o participante completamente independente do IPv4 na LAN de peering.
Como o route server usa a SLAT
O mecanismo funciona da seguinte forma. Quando qualquer participante anuncia uma rota IPv4 ao route server, o RS converte imediatamente o next-hop para o endereço IPv6 do anunciante, consultando a SLAT. A partir desse momento, internamente, todas as rotas IPv4 têm next-hops IPv6.
Na hora de distribuir uma rota para um Unnumbered Speaker, o RS a envia com o next-hop IPv6. Nenhuma conversão adicional necessária.
Na hora de distribuir uma rota para um Legacy Speaker, o RS consulta a SLAT e substitui o next-hop IPv6 do anunciante pelo endereço IPv4 sintético correspondente, na coluna específica daquele Legacy Speaker. O Legacy Speaker recebe a rota com um next-hop IPv4 local e a instala em sua tabela de roteamento normalmente.
O problema do ARP e a solução do proxy
O Legacy Speaker, ao tentar encaminhar tráfego para esse next-hop IPv4 sintético, vai emitir uma consulta ARP: “quem tem o endereço 192.0.2.X?”. Para responder a essa consulta, o IXP precisa ter um ARP proxy configurado. O proxy intercepta consultas ARP da LAN de peering, consulta a SLAT para descobrir qual MAC corresponde a qual IPv4 sintético, e responde em nome do dono daquele endereço. O Legacy Speaker recebe a resposta, aprende o MAC e encaminha o frame Ethernet para o destino correto. Pelo mesmo motivo, o draft também trata de ND proxy e de filtragem para evitar que ARP e ND sejam simplesmente repassados entre clientes.
É um processo transparente para o Legacy Speaker: ele faz um ARP normal e recebe uma resposta normal. Por baixo dos panos, há uma indireção gerenciada pelo IXP.
Esse detalhe é importante: a tradução não muda o pacote IPv4 do usuário. Ela muda apenas a forma como o roteador legado descobre o MAC associado ao next-hop apresentado pelo route server.
O IXP Interconnection Space
Os endereços IPv4 sintéticos precisam vir de algum lugar. O draft propõe que a IANA aloque um /8 da faixa 240/4 como bloco IPv4 de uso especial, chamado de “IXP Interconnection Space”, especificamente para essa finalidade. Usar um bloco padronizado traz duas vantagens: os membros de diferentes IXPs que utilizarem o mesmo bloco compartilham a mesma convenção, reduzindo o tamanho das tabelas SLAT; e evita conflitos com endereços roteáveis na Internet pública, já que esses endereços sintéticos jamais devem ser anunciados para fora do IXP. Como se trata de um Internet-Draft, essa alocação ainda é uma proposta.
A limitação importante: peerings bilaterais
O mecanismo descrito resolve a tradução no contexto das sessões via route server. Peerings bilaterais diretos, em que dois membros estabelecem sessão BGP diretamente entre si sem passar pelo RS, não são resolvidos automaticamente pelo route server. Para esses casos, ambos os peers precisariam suportar RFC 8950 entre si, manter endereços IPv4 na interface especificamente para essas sessões ou implementar a tradução por conta própria com base em informações publicadas pelo IXP.
Em IXPs de grande porte, os peerings bilaterais podem ser numerosos. Essa limitação é real e precisa ser considerada no planejamento. O draft reconhece isso explicitamente e trata o caso bilateral como responsabilidade dos próprios participantes, ainda que sugira que a SLAT seja disponibilizada publicamente para facilitar traduções fora do route server.
O IX.br será IPv6-only?
O IX.br será IPv6-only?
O IX.br ainda não oferece RFC 8950 em seus route servers, e não há ainda um cronograma para implantação. Não há urgência, visto que a pressão de endereçamento IPv4, no contexto do LACNIC, ainda não é preocupante. Não há uma definição formal para adoção. Não confunda este artigo com um anúncio da adoção de route servers IPv6-only pelo IX.br. Ainda assim, a direção da Internet é clara. O IPv6 avança em adoção global de forma consistente. A escassez de IPv4 aprofunda-se gradualmente. E a comunidade técnica internacional demonstrou, com três anos de trabalho documentado e resultados em produção, que a RFC 8950 é viável em escala real.
O modelo distribuído do IX.br, com PTTs em 39 áreas metropolitanas, oferece uma vantagem natural para uma eventual futura transição gradual. É possível experimentar em um PTT de menor porte, aprender com a experiência, ajustar a abordagem e expandir para os demais sem afetar o ecossistema inteiro de uma só vez.
O que os ISPs e operadores de AS brasileiros podem fazer agora é se preparar com antecedência. Sem pressa. Sem alarme.
O primeiro passo é entender o novo padrão, familiarizar-se com o conceito. Este artigo tem a pretensão de ajudar nisso. O segundo passo é o inventário: quais roteadores de borda têm suporte à RFC 8950? Em qual versão de sistema operacional o suporte foi introduzido? A tabela de compatibilidade acima é um bom ponto de partida. O passo seguinte é experimentar, é o laboratório. Montar um ambiente de simulação com Containerlab é gratuito e acessível. É possível simular uma LAN de peering com um route server RFC 8950 e alguns roteadores virtuais em poucas horas. Ver como a capacidade Extended Next Hop é negociada no OPEN, como o next-hop IPv6 aparece nas tabelas de roteamento, como o traceroute se comporta sem IPv4 na interface, tudo isso em laboratório, sem risco para a rede de produção. O repositório euro-ix/rfc8950-ixp no GitHub tem exemplos prontos para Containerlab e guias de configuração por fabricante.
Finalmente, um passo importante é acompanhar as discussões no IETF, em particular o draft de Matějka e Wagner, na lista do GROW, que está em fase de discussão pública. Participar ou ao menos ler os comentários da comunidade técnica internacional é uma forma eficiente de acompanhar como o problema do legado está sendo endereçado antes que ele chegue ao ambiente brasileiro.
Conclusão
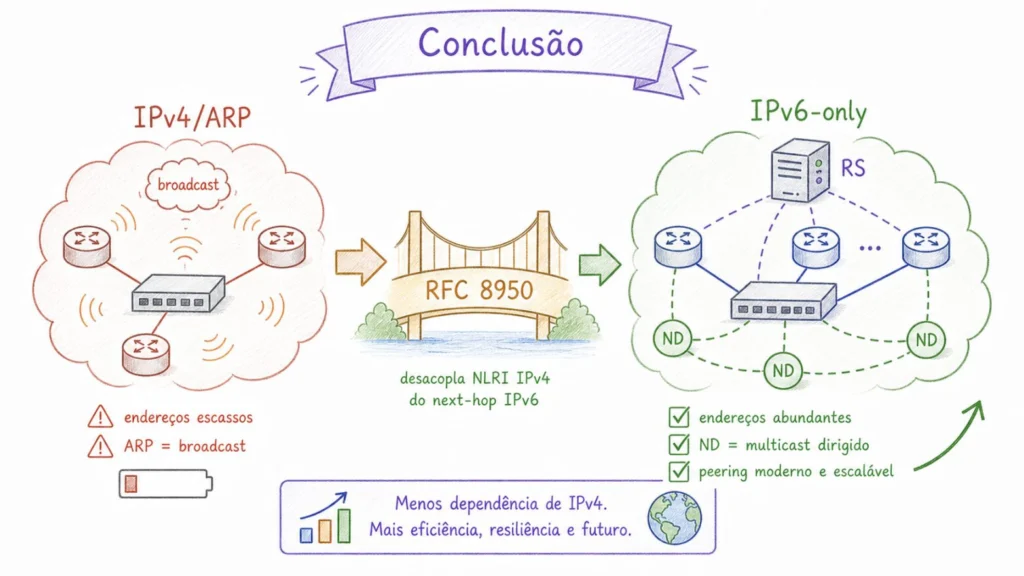
Evolução técnica que já está em curso
A transição dos IXPs para operação IPv6-only nas sessões de route server não é uma ruptura repentina. É uma evolução técnica que já está em curso, com padrão consolidado, ferramentas maduras e resultados comprovados em produção em IXPs reais.
A RFC 8950 resolve uma limitação técnica real do protocolo BGP: desacopla a família de endereços do NLRI da família do next-hop, permite negociação incremental peer a peer e elimina a dependência de endereços IPv4 na LAN de peering nos cenários em que todos os participantes relevantes suportam a técnica. O resultado não é apenas economia de endereços IPv4: é também uma peering LAN mais limpa, com menos dependência de broadcast ARP e com resolução de vizinhança concentrada no plano IPv6. O draft complementar de Matějka e Wagner endereça o cenário de coexistência com peers legados, viabilizando uma transição gradual em IXPs de grande porte, embora ainda seja trabalho em andamento.
No Brasil, o momento é de estudo e preparação. A pressão operacional ainda não é urgente, o IX.br não tem planos imediatos de mudança, e alguns fabricantes amplamente usados na região ainda têm pendências de implementação. Mas a Internet caminha para o IPv6, e quem começar a entender e testar a RFC 8950 hoje chegará ao momento da transição com muito mais tranquilidade do que quem esperar para aprender quando a necessidade for imediata.
O caminho está mapeado, a documentação está disponível, e o Containerlab já permite testar a ideia sem risco para a rede de produção. Monte o laboratório, veja como funciona, depois nos conte sua experiência.
Referências
- RFC Editor. RFC 8950: Advertising IPv4 Network Layer Reachability Information (NLRI) with an IPv6 Next Hop, novembro de 2020.
- IETF Datatracker. draft-marenamat-grow-route-server-nh-translation-01: Route Server Next Hop Translation, 27 de fevereiro de 2026.
- Euro-IX. Repositório rfc8950-ixp, incluindo README, exemplos e apresentações.
- Euro-IX mailing list. Concluding the RFC8950-IXP Working Group, março de 2026.
- CGI.br/NIC.br. IX.br bate recorde de 50 Tbit/s de tráfego Internet agregado, 20 de março de 2026.
- LACNIC. Fases de Esgotamento do IPv4 e Manual de Políticas, seção 2.3.5.
- LACNIC. critical-infra-latest, arquivo público de estatísticas da reserva de infraestrutura crítica.
- RIPE NCC. Policy Proposal 2023-01: Reducing IXP IPv4 assignment default size to a /26, aceita e implementada em 14 de setembro de 2023.
- RIPE 88. Removing IPv4 Infrastructure Addressing from Meta’s Edge Network, maio de 2024.
- IPv4.Center. IPv4 Market Report 2026, março de 2026.
- PeeringDB. AS60550 – DeepL SE.
As opiniões expressas pelos autores deste blog são próprias e não refletem necessariamente as opiniões de LACNIC.