Arquitectura IPv6 y subnetting: una guía para ingenieros y operadores de redes
06/07/2023

Daryll Swer, Ingeniero de sistemas y redes
Esta publicación es una adaptación del original publicado en el blog de Daryll.
A medida que las redes continúan creciendo, la necesidad de una gestión eficaz del Protocolo de Internet versión 6 (IPv6) se vuelve cada vez más importante. Esta guía está diseñada para ingenieros y operadores de redes que ya están familiarizados con los fundamentos y conceptos básicos de IPv6 y que buscan una guía práctica sobre la implementación de una arquitectura IPv6 y un plan de subnetting. Aquí analizo en profundidad las formas más eficientes de garantizar un modelo de subnetting para el despliegue de IPv6 por sitio y por segmento de red, que sea suficiente y que esté preparado para el futuro.
Para quienes necesiten repasar los fundamentos de IPv6, hay muchos recursos disponibles en línea que les podrán ayudar.
Este artículo se basa en mi experiencia como consultor independiente y como colega en diferentes industrias, entre ellas las telecomunicaciones, los datacenters/redes empresariales y los ISP. En mis conversaciones con otros ingenieros de redes noté una cierta resistencia a aprender los conceptos básicos de IPv6 o una dependencia excesiva de los procesos arcaicos de IPv4. El objetivo de esta guía es presentar una descripción completa de la arquitectura y el subnetting en redes IPv6 para implementar IPv6 de manera eficiente y evitar las trampas de una mentalidad centrada en IPv4, como se explica más detalladamente en el podcast a continuación.
Los riesgos asociados con una implementación o administración ineficiente de IPv6 son bien conocidos. Desde un punto de vista administrativo, puede conducir a un subnetting desordenado y no escalable, cuyo resultado serán redes frágiles y poco confiables. Desde el punto de vista de la ingeniería, puede llevar al uso injustificado de pequeñas subredes y forzar la necesidad de utilizar traducción de direcciones de red (NAT66) cuando no es necesario. Esto va de la mano con la idea de usar direcciones locales únicas (ULA) cuando no es necesario, todo lo cual es un serio impedimento para el objetivo final de ofrecer un servicio de red eficiente, confiable y escalable, a la vez preservando el principio de extremo a extremo en la capa de red para minimizar o eliminar las complejidades que provoca la NAT, tales como el uso de helpers (ayudantes) y técnicas de NAT Traversal para ciertos protocolos.
A continuación, se incluyen algunos ejemplos de lo que sucede cuando una organización intenta desplegar IPv6 con un enfoque centrado en IPv4:
- Si no hay un plan adecuado para la gestión del subnetting de IPv6, a los enlaces punto a punto (PtP), los servidores y demás elementos de infraestructura se le asignan prefijos/direcciones IPv6 aleatorios, lo que genera una situación caótica e imposible de manejar. A la larga, esto podría llevar a un problema de tipo “carrera hacia el fondo” (quedarse sin direcciones IPv6), una situación que debe evitarse a toda costa para mantener la red segura y escalable.
- Un único prefijo de LAN /64 por cliente/CPE o, peor aún, un prefijo mucho más largo (menor).
- Un prefijo para LAN dinámico que cambia cada vez que el usuario se vuelve a conectar e interrumpe la conectividad.
- La extraña idea de que IPv6 es IPv4 y que se debería usar NAT66 para “ahorrar” direcciones IPv6. Un ejemplo público de esto es la idea de DigitalOcean de un /124 por máquina virtual (VM) y de un /64 compartido por segmento de datacenter/rack/red.
- La idea aún más extraña de usar direcciones locales únicas (ULA) en ciertos casos en los que esto no es necesario.
- A excepción de los bancos u otras organizaciones similares donde el cumplimiento de ciertas políticas exige NAT66, o salvo que lo necesite debido al espacio de direcciones agregable por el proveedor (Provider-Aggregatable o PA) para el balanceo de carga y alta disponibilidad.
Si bien la versión del principio de extremo a extremo de la era anterior a NAT, en general, ya no existe en la era actual de Internet debido a la obsesión con IPv4, sigue siendo importante evitar NAT66 para prevenir la necesidad de aplicar helpers en las Capas 5-7 (Puertas de enlace de la capa de aplicación) y TURN (Traversal Using Relays around NAT) que solo agrega complejidades y sobrecarga la red cuando creamos redes para uso a gran escala. Este tráfico “ayudante” consume recursos innecesarios que se podrían evitar por completo.
En resumen, una mala arquitectura y subnetting de IPv6 genera una deuda técnica para nuestra organización a largo plazo.
Cosas que hay que tener en cuenta en IPv6
Hay algo que no podemos perder de vista con IPv6. Utiliza un formato de direcciones de 128 bits y la estructura matemática de IPv6 permite un /48 por persona durante 480 años. Esto significa que no hay ninguna justificación técnica para usar una delegación de prefijo menor que /56 por cliente, lo cual también está documentado en la BCOP 690.
Al desplegar IPv6, hay que tener en cuenta lo siguiente:
- El prefijo del enlace (o prefijo WAN) se utiliza para la conectividad entre dispositivos.
- El prefijo enrutado (o prefijo de la LAN) se refiere al prefijo que se enruta hacia el lado “LAN” de un dispositivo donde la IP next-hop de esa ruta es igual a la dirección link-local que se usa en el dispositivo hacia el cual se enruta el prefijo.
- Siempre hay que intentar habilitar la configuración automática de las direcciones link-local en toda la red; nunca debemos sobrecargarnos con la configuración manual del direccionamiento link-local.
- Evitar usar la dirección cero de una subred IPv6 en una interfaz o segmento de red, es decir, una dirección donde el segmento menos significativo de la dirección (o sea, el grupo de cuatro dígitos más a la derecha) son ceros. Se sabe que esto provoca comportamientos inesperados. Por ejemplo, en vez de 2001:db8::, usar 2001:db8::1.
- Sin embargo, se deberían poder usar las direcciones cero de las subredes únicamente para loopback en dispositivos de red (routers, switches L3) si así lo deseamos. De todos modos, yo evitaría usar las direcciones cero en los hosts.
A continuación, un ejemplo de los principios descritos anteriormente:
Prefijo de enlace
Digamos que queremos conectar el router A al router B mediante un cable de red UTP Cat6a en la interfaz eth0 de ambos y supongamos que tenemos el siguiente prefijo disponible: 2001:db8::/64.
Configuraremos las direcciones de la siguiente manera:
router A (eth0): 2001:db8::1/64
router B (eth0): 2001:db8::2/64Ambos routers tienen un prefijo de enlace /64, donde ahora pueden comunicarse directamente entre sí en las respectivas direcciones asignadas ::1 y ::2.
Prefijo enrutado
Supongamos que el router B es un router de capa de acceso donde está configurado para manejar 500 VLAN, que tenemos al menos 800 PC detrás de cada VLAN y que queremos brindar conectividad IPv6 nativa a 800×500 hosts. ¿Cómo podemos hacerlo con el prefijo de enlace /64 de forma nativa y dejando de lado la mentalidad de IPv4 y enfoques como el de NAT66 o NDP Proxy? La respuesta es que no usamos un prefijo de enlace para la LAN. Necesitamos un prefijo enrutado, donde cada VLAN tenga un /64 dedicado. En este ejemplo, necesitamos un total de quinientos /64.
Entonces, supongamos que para el prefijo de LAN al que se puede acceder a través del router A tenemos lo siguiente: 2001:db8:1::/52.
Un /52 nos da cuatro mil /64, que es más que suficiente para nuestro propósito, incluso con margen para el crecimiento y la expansión en el futuro.
A los efectos de este ejemplo, ahora podemos enrutar estáticamente el /52 al router B de la siguiente manera, donde next-hop/uerta de enlace es la dirección IPv6 del router B:
ipv6 route 2001:db8:1::/52 next-hop 2001:db8::2Ahora podemos usar 2001:db8:1::/52 en el router B y dividirlo en subredes para obtener prefijos /64, de los cuales podemos asignar un /64 único por VLAN. Por ejemplo, VLAN1 obtiene 2001:db8:1::/64, VLAN2 2001:db8:1:1::/64 y así sucesivamente.
Tamaño de las asignaciones
Sin embargo, para las empresas más pequeñas podría ser suficiente un /48 o un /44 o un /40 y así sucesivamente. No recomiendo adoptar este método de asignaciones incrementales por las siguientes razones:
- No podemos agregarlos dentro de diez años cuando escale su empresa.
- Genera una tabla de enrutamiento IPv6 contaminada que podría evitarse mediante la agregación.
- Tendrá un impacto en nuestra arquitectura y plan de subnetting.
- Eventualmente acabaremos por necesitar más subredes.
- Terminaremos yendo y viniendo con nuestro respectivo Registro Regional de Internet (RIR), Registro Nacional de Internet (NIR) o Registro Local de Internet (LIR).
Mi recomendación es solicitar como mínimo un /32 por número de sistema autónomo (ASN) o cuenta de miembro en el RIR:
- Podemos agregar en un /32 de ser posible, en varios /36 o en cualquier combinación según la escala y la topología de nuestra empresa.
- Mantiene limpia la tabla de enrutamiento.
- Tenemos una arquitectura y un plan de subnetting escalables.
- Hay lugar para subredes adicionales.
- Se reduce la necesidad de tener que ir y venir con nuestro respectivo RIR, NIR o LIR.
Espero que alguien (o yo mismo) finalmente envíe una propuesta de política para hacer que esto (mínimo un /32 por ASN/Miembro) una realidad a nivel de RIR, al menos para APNIC.
Si te interesa conocer otras perspectivas, puedes escuchar el podcast de Packet Pusher sobre este tema.
Lineamientos para el subnetting
Las redes y las organizaciones son todas diferentes, lo que incluye diferentes modelos comerciales y arquitecturas y topologías de red. En el caso del subnetting de IPv6, a mí me gusta usar lo que llamo el modelo de denominación geográfica, es decir, planificamos y hacemos el subnetting según cómo esté configurada la red en el mundo físico, siempre pensando en estar preparados para el futuro (tanto para escalar hacia arriba como hacia abajo).
Más adelante mostraré algunos ejemplos de implementaciones prácticas en la vida real para ISP/empresas de telecomunicaciones y datacenters/redes empresariales.
Teniendo en cuenta lo anterior, creo firmemente que lo que sigue constituye una guía optimizada y generalizada que los operadores podrían seguir:
- Tal como se explicó en la sección anterior, lo mínimo que debe tener cada router eBGP (ASN público) es un prefijo /32.
- Preparar la planificación en función del modelo de distribución geográfica de nuestra red con un enfoque de arriba a abajo. Por ejemplo, por continente, después por economía, después por estado, después por ciudad, después por pueblo o distrito, después por sitio y por segmento de red.
- Verificar que la longitud de prefijo sea siempre múltiplo de 4, siendo la denominación más baja posible un /64, nada más pequeño, ya que queremos evitar exceder el límite del nibble.
- Sin embargo, a veces no podemos evitar exceder el límite del nibble, lo que no es un problema si el “exceso” permanece en una capa administrativa y nunca ingresa a la capa de red. En la sección sobre arquitectura voy a destacar esto con un ejemplo de la vida real.
- Algunos prefieren usar prefijos /126 o /127 para los peerings eBGP con terceros y para los enlaces PtP entre dos dispositivos. En estos casos, reservaremos todo un /64 por interfaz (o peer) para cada /126-/127 que usamos, por si en el futuro decidimos escalar el puerto/la interfaz garantizando que siempre haya un /64 disponible en el IPAM y así evitamos registros de subnetting o direccionamiento desordenados.
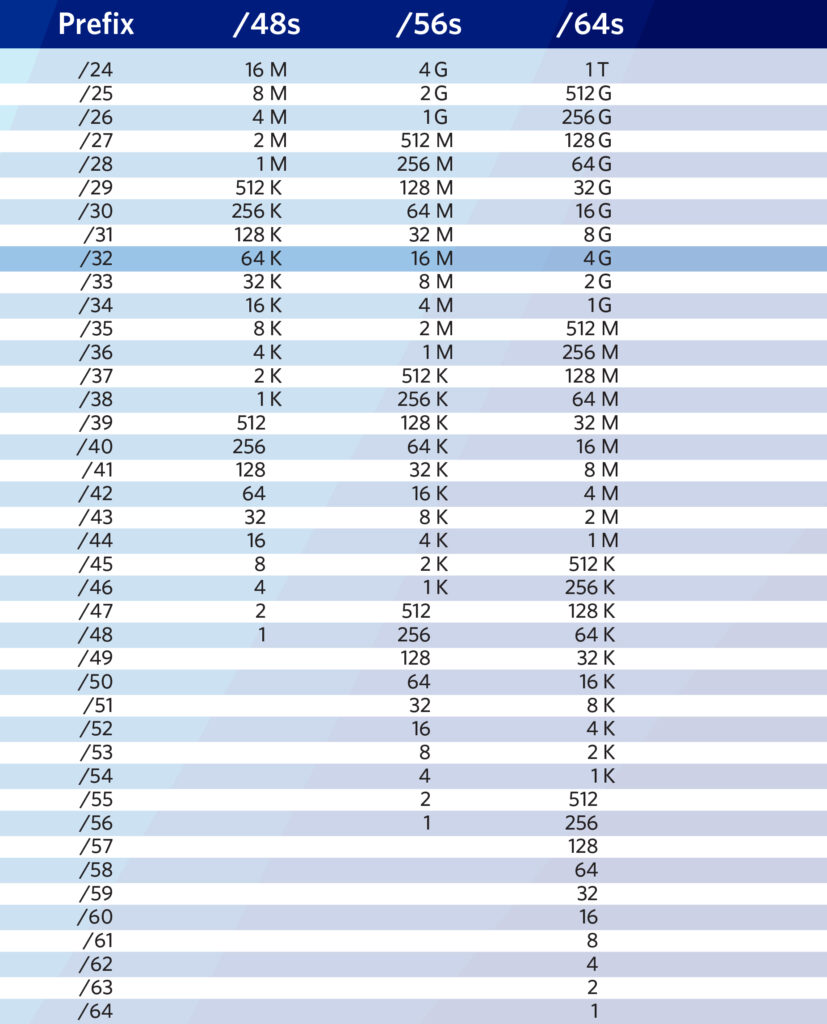
Figura 1: Ayuda memoria para IPv6 de APNIC. Fuente.
Ejemplo de los principios anteriores
Supongamos que nuestro prefijo asignado por el RIR es el 2001:db8::/32. Podemos dividir el 2001:db8::/32 en /36. De los /36 resultantes, podemos usar los primeros cuatro para las partes norte, este, oeste y sur de una economía/un estado/una ciudad y así sucesivamente, donde cada denominación geográfica recibe un /36.
A un /36 lo podemos dividir en un /40 por punto de presencia (PoP) (sitio), a partir de lo cual podemos continuar dividiendo en /44 y luego en /48. Luego podemos usar un /48 por función, por ejemplo, fuera de banda (OOB), administración, servidores internos, switches, PtP, etc. Después podemos dividir el /48 en /52 o /56 para asegurarnos de obtener una cantidad suficiente de prefijos /64 por dispositivo. Podemos usar un /64 por segmento de VLAN/VXLAN donde tomamos un /127 para enlaces PtP y le reservamos todo el /64, en caso de que en el futuro los enlaces crezcan hasta tener un enlace multipunto. Cuando un /127 ya no sea suficiente, podemos usar todo el /64 reservado sin tener que cambiar el plan de subnetting/gestión de direcciones IP (IPAM).
Cabe notar que lo anterior es solo un ejemplo. IPv6 es flexible y se puede dividir en subredes de manera que coincida con la distribución geográfica de nuestra red, que puede variar. Siempre que sigamos las pautas generales, deberíamos poder escalar hacia arriba o hacia abajo sin demasiados problemas.
Personalmente, dejé de usar prefijos /126 y /127 en enlaces PtP porque no ofrecen ningún beneficio y solo aumentan la carga de gestión humana. Por lo tanto, en adelante recomiendo el uso de un /64 regular por interfaz PtP desde el primer día.
Arquitectura
En esta sección me referiré a dos categorías, datacenters/redes empresariales y empresas de telecomunicaciones/ISP, aunque, en términos generales, la guía sobre subnetting se puede utilizar de manera similar para ambas. Sin embargo, existen diferencias técnicas y de modelo comercial, que creo que se entenderán mejor a partir de algunos ejemplos de la vida real basados en mi propia experiencia práctica.
Datacenters/redes empresariales
Presentaré un ejemplo real aunque más generalizado que se desplegó en producción en la red de mi empleador anterior (AS48635) para mostrar cómo implementamos los lineamientos anteriores para satisfacer nuestras necesidades específicas.
Contexto
En este ejemplo de la vida real, decidí usar un solo /32 para infraestructura/backbone en múltiples economías, ubicaciones y sitios, ya que era suficiente para el modelo de denominación geográfica de esta organización en particular. Sin embargo, para los clientes opté por un /32 dedicado para cada sitio de manera de garantizar la escalabilidad a futuro, con muchos /48 o /56 enrutados a ellos según fuera necesario.
Para el backbone
Así es cómo decidí dividir el único /32 para el direccionamiento de la subestructura/ backbone “global”:
- Dividimos el /32 en /36, usamos el primer /36 y reservamos el resto para uso futuro.
- Luego dividimos el primer /36 en /40, usamos el primer/40 y reservamos el resto para uso futuro.
- Luego dividimos el primer /40 en /44 y usamos un /44 por sitio.
- Aquí, podemos reservar el primer /44 para experimentos/pruebas en caso de que alguna vez sean necesarios.
- Luego dividimos un /44 en /48. Aquí usamos un /48 por función por sitio.
Un /48 por función un cada sitio se divide de la siguiente manera:
- Función IP de loopback: un /48 dividido en /64. Usamos un /64 por “fila” de tipo de dispositivos en una topología dada, lo que simplifica la legibilidad y los filtros de enrutamiento para OSPF/IS-IS en cada fila de dispositivos. Simplemente filtramos la importación/exportación para que coincida con un /64. Por último, asignamos un /128 por dispositivo para loopback. Por ejemplo, un /64 para dispositivos perimetrales, otro /64 para dispositivos core o de distribución, etc., donde cada tipo de dispositivo obtiene un /128 del respectivo /64.
- Función OOB: Un /48 dividido en un /52 por cada subfunción, por ejemplo:
- Función PtP intra/inter AS: Un /48 dividido en /52 por cada “fila” de dispositivos en una topología determinada. Por ejemplo, un /52 para el borde, un /52 para distribución Capa 3, un /52 para los BNG y así sucesivamente.
- Después, cada /52 se divide en /64 para usarlos en cada “fila” de dispositivo correspondiente. Por ejemplo, se asigna un /52 al borde, del cual luego se divide un /64 por interfaz/VLAN.
- Función de peering (tránsito, PNI, etc.): Un /48 dividido en un /64 por peer.
- Switches Top-of-Rack (ToR): un /48 para todos los ToR en un sitio, un /55 por rack, luego un /56 por dispositivo ToR. Por último, de un /56 para cada dispositivo ToR, lo dividimos en /64 para usarlos por puerto (o segmentos de VLAN) para hosts finales como SLAAC o DHCPv6, con capacidad de hasta 256 puertos/VLAN por dispositivo ToR.
- Este es un ejemplo en el que se “excedió” el límite del nibble en la capa administrativa (/55) sin penetrar la capa de red y, por lo tanto, no presenta ningún problema técnico.
Para el cliente
Para el pool de clientes /32, idealmente la lógica debería ser más simple que la del backbone para evitar dolores de cabeza en el futuro a medida que aumente la cantidad de clientes.
En la red de mi empleador, decidimos que el grupo mínimo para un cliente sería /56. Sin embargo, compartiré un enfoque más generalizado que no es específico de la lógica empresarial de mi empleador. Siempre podemos optar por un /48 por cliente si así lo deseamos; esto permite una mayor flexibilidad para que el cliente haga subnetting y enrute los prefijos a sus máquinas virtuales correspondientes de la forma que desee.
Para la lógica /56:
- Dividimos el /32 en /40 para obtener 256 /40. Tomamos el primer /40, lo dividimos en /48 y obtenemos 256 /48.
- Este pool de /48 se usará como un /48 por rack para el enlace PtP entre un hipervisor y la interfaz WAN de la máquina virtual del cliente. Esto significa que cada rack obtiene un /48 y cada /48 se divide en prefijos /64.
- Por lo tanto, ahora tenemos 65k /64. Cada rack ahora puede soportar 65k máquinas virtuales, donde la interfaz WAN de cada máquina virtual obtiene un /64.
- Sin embargo, puede que también queramos utilizar un /64 para un único dominio L2 en múltiples máquinas virtuales, por lo que una VLAN o “VPC” de un cliente tiene un solo /64 para la interfaz WAN de las máquinas virtuales, y así cada máquina virtual recibe un /128.
- A continuación, usaremos los /40 restantes para proporcionar prefijos enrutados a la máquina virtual de cada cliente. Cada rack obtendrá un /40 dedicado del pool original de prefijos /40 obtenido a partir del /32.
- Ahora que cada rack tiene un /40 dedicado, tenemos 65k /56.
- Ahora simplemente enrutamos un /56 a la máquina virtual de cada cliente. Así, todos los clientes tendrán su propio pool dedicado de /56 para sus propios usos en cada máquina virtual, que es mucho más de lo que hace la mayoría de los proveedores de nube y, por lo tanto, es un enfoque que, a la larga, está preparado para el futuro.
Para la lógica /48:
- Dividimos el /32 en /48. Esto nos da 65k /48. Podemos, por ejemplo, utilizar/reservar los primeros 10k /48 para el enlace PtP entre un hipervisor y la interfaz WAN de la máquina virtual del cliente. Esto significa que podemos manejar 10k hipervisores, donde la interfaz WAN de cada máquina virtual obtendrá un /64 o un dominio L2 completo obtendrá un /64, y donde cada máquina virtual dentro del dominio L2 obtendrá un /128.
- Ahora simplemente enrutamos/mapeamos un /48 a cada cuenta de cliente. Cada cliente obtendrá su propio /48 y luego lo dividirá en subredes según sea necesario, o podemos hacer que por defecto el subnetting sea un /56 enrutado por cada máquina virtual y permitir que el cliente cambie el subnetting si así lo desea.
Cualquiera de los dos enfoques está perfectamente bien. Sin embargo, probablemente hayas notado que el enfoque basado en /56 tiene una sobrecarga adicional en la capa de red, mientras que el enfoque basado en /48 tiene menos sobrecarga en la capa de red pero más sobrecarga en la capa de aplicación, ya que le deberemos proporcionar una interfaz web o CLI para que nuestro cliente haga subnetting y divida su propio /48 si así lo desea.
Dado que es un /32 por sitio, no genera confusión ni un IPAM/subredes desordenados. Podemos simplemente anunciar cualquier /48 de los ToR hacia los switches de distribución L3 (o la puerta de enlace VXLAN/VTEP), que luego lo anuncia a los routers de borde. Siempre podemos realizar la agregación de rutas en cada capa de dispositivos para minimizar la tabla de enrutamiento en nuestra red local.
En resumen, para el pool de clientes en los datacenters/redes empresariales, podemos optar por un /48 por cliente (personalmente prefiero esto para evitar seguir dividiendo en subredes y aumentar la posibilidad de que los clientes soliciten más /56) o un /56 por máquina virtual del cliente, de modo que cada máquina virtual aún obtendrá un /56.
Topología
Es importante señalar que el siguiente diagrama se incluye solo a modo de referencia para darle al lector una idea del subnetting de IPv6. Se trata de un diagrama de una topología más pequeña y simplificada que la topología en producción, que es mucho más grande y compleja y no cabría en un solo diagrama.
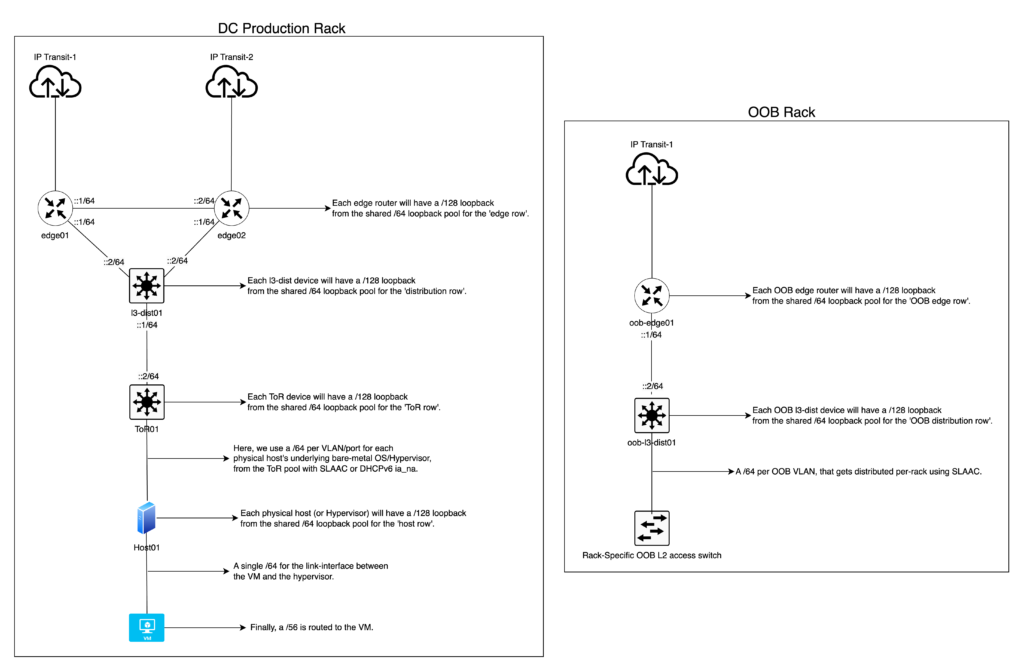
Figura 2: Ejemplo de topología.
ISP/Empresa de telecomunicaciones
Cubriré esto con un ejemplo de la vida real que diseñé para AS141253 (uno de mis upstream providers al momento de escribir este artículo) para implementar una arquitectura IPv6 para su red que abarca la totalidad de la India, un buen ejemplo de una red a gran escala.
Dado que se basa en la denominación geográfica de India (economía > estado > distrito > etc.), creo que es un buen ejemplo por su tamaño y gran población. Por motivos de escalabilidad y de preparación para el futuro, recomiendo tener como mínimo un pool de clientes /32 asignado por estado.
Ejemplo de contexto
Tienen un prefijo /32 “Global” para un backbone nacional y, al momento de escribir este artículo, hay un prefijo /32 de “clientes” exclusivamente para el estado de Mizoram.
Como fuente de verdad, para la denominación geográfica de la India hasta el nivel estatal utilicé este documento gubernamental.
Para el backbone
Así es como decidí dividir el único /32 para el direccionamiento de la subestructura/backbone “global” de India:
- Dividimos el /32 en prefijos /34 y usamos cada /34 (otro ejemplo de longitud de prefijo fuera del límite del nibble, pero solo en una capa administrativa) para cada zona geográfica (norte, este, sur, oeste).
- Luego dividimos cada /34 en prefijos /40 y usamos un /40 por estado/territorio in el mapeo de cada zona respectiva. Esto nos da 64 /40.
- Si bien esta delegación adicional no es obligatoria, prefiero reservar un número “par” de /40 para cada estado. Por ejemplo, la zona “India del Norte” tiene un total de ocho estados. Si dividimos 64 por ocho (la cantidad de estados en una zona), el resultado es ocho. Esto significa que cada estado tiene un total de ocho /40 asignados, lo que ayuda con los gastos administrativos y mantiene los prefijos alineados geográficamente en orden alfabético/serial.
- Luego dividimos el primer /40 en /44 y usamos un /44 por sitio.
- Aquí, podemos reservar el primer /44 para experimentos/pruebas en caso de que alguna vez sean necesarios.
- Luego dividimos un /44 en /48. Aaquí usamos un /48 por función en un sitio determinado.
Un /48 por función en un sitio determinado se divide de la siguiente manera:
- Función IP de loopback: un /48 dividido en /64. Usamos un /64 por “fila” de tipo de dispositivos en una topología dada, lo que simplifica la legibilidad y los filtros de enrutamiento para OSPF/IS-IS en cada fila de dispositivos. Por último, asignamos un /128 por dispositivo para loopback. Por ejemplo, un /64 para dispositivos perimetrales, otro /64 para dispositivos core o de distribución, etc., donde cada tipo de dispositivo obtiene un /128 del respectivo /64.
- Función OOB PtP: un /48 dividido directamente en /64, lo usamos para cada interfaz/VLAN en enlaces PtP dentro de la red OOB, por ejemplo, un enlace PtP entre los routers OOB de borde.
- OOB/función de gestión y similares: un /48 por sitio dividido directamente en /64 y usamos un /64 por VLAN OOB en un rack determinado (un solo rack; tiene una sola VLAN OOB para todos los dispositivos).
- Tomamos el primer /64 y lo dividimos en /128. Podemos usar cada /128 como IP de loopback para los routers OOB de borde, aunque esto no es obligatorio.
- También podemos reservar un /64 para que clientes o empleados de la VPN accedan para gestionar la red y el backbone de cada sitio.
- Función PtP intra/inter AS: un /48 dividido en /52 por cada “fila” de dispositivos en una topología determinada. Por ejemplo, un /52 para el borde, un /52 para distribución Capa 3, un /52 para los BNG y así sucesivamente.
- Luego dividimos cada /52 en /64 para usarlos en cada “fila” de dispositivos correspondiente, por ejemplo, se asigna un /52 al borde, del cual luego se dividen prefijos /64 por interfaz/VLAN.
- Función de peering (tránsito, PNI, etc.): un /48 dividido en prefijos /64. Si no usamos todo el /64, creamos un /126-127 y lo reservamos para uso futuro en caso de que queramos escalar ese puerto/segmento de red específico en múltiples VLAN o una interfaz multipunto.
- Nodo de almacenamiento en caché de CDN: un /48 dividido en /56 por CDN. Por ejemplo, un /56 para Google, dividido en /64 para usar en enlaces PtP o para prefijos enrutados garantiza que cada equipo/nodo de almacenamiento en caché de CDN tenga hasta 256 prefijos /64 disponibles para usar en un sitio.
En definitiva, esto es para el backbone, no para el pool de clientes. Por lo tanto, un solo /32 puede cubrir toda la red para India.
Esta planilla Excel que preparé para AS141253 muestra un ejemplo de los principios descritos.
Para el cliente
El pool de clientes /32 para el estado de Mizoram se divide en prefijos /37. De estos, dieciséis /37 se reservan para clientes empresariales/comerciales, mientras que los dieciséis /37 restantes se reservan para clientes residenciales.
Después cada grupo de dieciséis /37 se mapea respectivamente a cada distrito del estado, donde cada distrito obtiene un /37, aunque hay mucha mayor disponibilidad en el caso que sea necesario. Si no se conoce el número exacto de distritos, condados o provincias, se puede dividir el /32 en /38 o incluso más, hasta obtener lo que mejor se adapte a nuestra denominación geográfica.
Es importante recordar que esto es simplemente a nivel administrativo, no a nivel de la capa de red. Sin embargo, recomiendo evitar profundizar demasiado en la jerarquía, con una regla general de que el prefijo más pequeño por BNG para el pool de LAN del cliente debería ser un /42, ya que esto considera que un /42 garantiza que 16k clientes obtendrán un /56 y nos permite estar preparados para el futuro, ya que probablemente deseemos limitar la cantidad de clientes por BNG a 16k o menos y repartir la carga en otros BNG para evitar crear un escenario de punto único de falla (SPOF). Incluso si agregamos clientes más allá de 16 000, solo necesitamos enrutar otro /42, lo que garantiza que 32k clientes por BNG obtendrán un /56 estático.
Así es como decidí dividir cada /37 por distrito para los clientes residenciales:
Cada /37 en un distrito determinado se divide en /42 y el primer /42 se divide en /48. Cada /48 se enrutará a cada BNG, por lo que proporcionará una distribución WAN /64 a cada cliente para hasta 65k clientes por BNG, lo que también es una forma de prepararse para el futuro. Los /42 restantes se distribuirán por BNG, donde cada /42 proporcionará /56 estáticos (persistentes) para hasta 16k clientes por BNG.
En resumen, los clientes residenciales obtendrán un /64 para el lado de la WAN y un /56 estático para el lado de la LAN.
Así es como decidí dividir cada /37 por distrito para los clientes empresariales:
Cada /37 en un distrito determinado se divide en /48 para su uso dentro del distrito especificado. A partir de aquí, podemos usar un /48 por sitio para el enlace PtP entre el proveedor y el cliente, donde se lo divide en prefijos /64 por interfaz/VLAN.
A continuación, simplemente enrutamos un /48 dedicado a cada cliente ya sea vía BGP con ASN privado o con enrutamiento estático del /48 a la dirección ::2/64 de la interfaz PtP del cliente.
En resumen, los clientes empresariales obtendrán un /64 para el lado de la WAN y un /48 estático /48 estático para el lado de la LAN.
Topología
Los ISP tienen una topología bastante típica. Si ya eres un ISP, es probable que ya tengas topologías similares. Naturalmente, la escala es mucho mayor que la de un operador de datacenter/red empresarial y completamente diferente, ya que en general tiene un borde, una capa de distribución (en algunos casos, un core y una distribución), una capa de acceso, anillos de conmutación de etiquetas multiprotocolo (MPLS), etc.
La topología ilustrada en el siguiente diagrama se incluye solo a modo de referencia para darle al lector una idea del subnetting de IPv6 para un ISP.
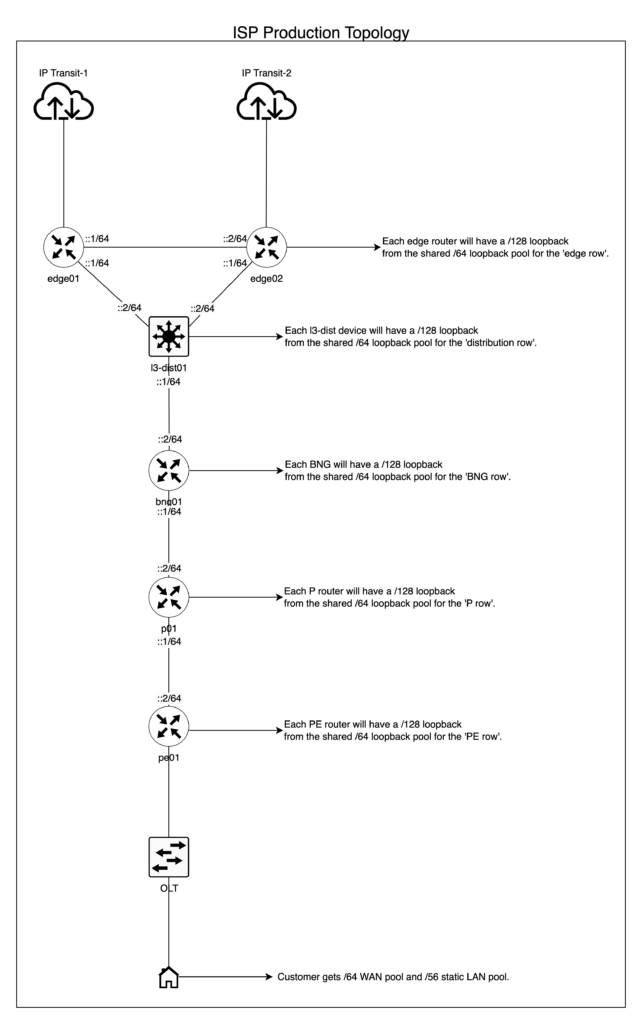
Implementación
Datacenters/redes empresariales
Usamos direccionamiento estático para enlaces PtP, Open Shortest Path First (OSPF) para aprender las IP de loopback de cada dispositivo, una combinación de eBGP e iBGP para enrutar todo lo demás y evitar iBGP de malla completa, y confederación BGP o reflectores de ruta basados en la RFC 7938. Para explicarlo en términos sencillos, iBGP se usa entre loopbacks de vecinos adyacentes/redundantes que forman una relación horizontal, por ejemplo, un conjunto de routers de borde, cada uno de ellos conectado a diferentes IXP o conexiones de tránsito. En cambio, eBGP se usa entre vecinos verticales que establecen una relación upstream/downstream en la que cada uno se encuentra en sistemas autónomos diferentes usando un rango extendido de ASN privados.
Para OOB, usamos SLAAC + EUI-64 para generar automáticamente direcciones en los dispositivos de red y hosts en la VLAN OOB que se mapean fácilmente a sus direcciones MAC. Esto significa que nuestros routers, switches, nodos de servidor, unidades de distribución de energía (PDU), etc., reciben una dirección unicast global (GUA) /128 vía SLAAC a través del switch OOB específico del rack, que luego obtiene conectividad del switch de distribución OOB en el rack OOB. Para las VLAN principales o en producción (máquinas virtuales o máquinas del cliente), debemos evitar usar EUI-64.
Si bien no implementé esta configuración usando asignación de direcciones DHCPv6 y delegación de prefijos en un datacenter/red empresarial, esta es una solución perfectamente válida si se prefiere un control stateful sobre cómo los hosts obtienen sus direcciones y también para fines de autenticación, autorización y contabilidad (AAA).
ISP
En este ISP en particular, la implementación fue sencilla. Usamos direccionamiento estático para los enlaces PtP del backbone, BGP/OSPF para el enrutamiento interno y/o para los clientes empresariales de manera similar al ejemplo de los datacenters/redes empresariales, usando PPPoE o DHCPv6-PD para delegar los /48 o /56 a los clientes. No profundizaré en los detalles de la implementación, ya que esto varía enormemente entre los diferentes fabricantes. Solo intentaré ofrecer una idea general y una guía para que podamos desplegar IPv6 de forma compatible con BCOP-690 en nuestra red.
Sin embargo, recomiendo utilizar un fabricante/proveedor de AAA que soporte direccionamiento/PD IPv6 estático para nuestros clientes. Como ya mencioné en la introducción, los prefijos dinámicos rompen SLAAC y también hacen que sea imposible que un cliente use su GUA en sus hosts finales para accesibilidad global si así lo desea.
¿Qué pasa con las VPN?
Podemos tener una función /48 dedicada para VPN en un sitio determinado, o bien se puede compartir con la función de administración, donde los clientes reciben una GUA /128 estable (estática) de un pool de /64. Ahora simplemente usamos un firewall con estado en el router o en el host del servidor VPN, donde aceptamos el tráfico establecido, relacionado y no rastreado y aceptamos ICMPv6, descartando el resto en la cadena de forward (iptables). Eso es todo. Nuestros clientes VPN tendrán IPv6 nativo sin ningún tipo de trucos y estarán completamente protegidos del mundo exterior. Por supuesto, aún deberemos aplicar la lógica de la lista de control de acceso, pero eso depende de cada organización y está fuera del alcance de este artículo.
Incluso podemos proporcionar prefijos enrutados a clientes VPN, donde a cada cliente se le puede enrutar un /64. Esto ayuda a que los empleados que trabajan en el desarrollo de aplicaciones en Docker tengan un /64 nativo enrutado directamente a sus laptops para redes de contenedores con IPv6 nativo.
Enfoque de enrutamiento global
En lugar de anunciar /48 individuales a la zona libre de ruta por defecto (DFZ) y aumentar el tamaño de la tabla de enrutamiento global, deberíamos apuntar a anunciar prefijos agregados tanto como sea posible para un sitio o un conjunto de sitios determinado. Por ejemplo, en vez de /48 individuales, podemos anunciar un prefijo /44 “backbone” directamente a todos nuestros peers y conexiones de tránsito. O si todos nuestros sitios tienen alcanzabilidad de Capa 2 directa entre sí y están lo suficientemente próximos geográficamente como para que la latencia no sea un problema, entonces podríamos simplemente anunciar el prefijo /32 “backbone” directamente desde todos los sitios hacia las conexiones de tránsito y los peers, manteniendo así la DFZ limpia. Para el pool de clientes, es solo cuestión de anunciar un /32 por sitio directamente a todos los peers y conexiones de tránsito.
Observar que este artículo no se ocupa del BGP ni de la ingeniería de tráfico. Quisiera destacar que agregar nuestros prefijos permite una ingeniería de tráfico más limpia y eficiente a largo plazo.
Uso de NAT66 vs. NPTv6
No profundizaré en NAT44, NAT66 o NPTv6, ya que exceden el alcance de esta publicación. Sin embargo, a continuación mencionaré algunos puntos a tener en cuenta, ya que en ciertos casos de uso se requiere NPTv6 (pero no NAT66).
NAT66 no es diferente de la NAT44 tradicional e incluso presenta los mismos problemas, como el hecho de romper los protocolos de Capa 4 (L4), forzando la necesidad de una puerta de enlace de capa de aplicación, y la lista continúa. La única diferencia es que NAT66 soporta direccionamiento IPv6. Por esta razón, el IETF ideó una nueva solución y método de “traducción” para IPv6 que está libre de los problemas que introduce la NAT, es decir, la traducción de prefijos de red de IPv6 a IPv6 (NPTv6).
NPTv6 es un mecanismo sin estado e independiente del transporte (L4) que se utiliza para traducir un espacio de direcciones a otro. Por lo tanto, conserva el principio de extremo a extremo en la capa de red y no introduce un mecanismo con estado que rompa los protocolos L4, algo que es imposible en la NAT tradicional sin estado.
Para que NPTv6 funcione según lo previsto (sin estado), los prefijos IPv6 “internos” y “externos” deben tener la misma longitud de prefijo. Por ejemplo, supongamos que nuestro prefijo interno es “200::/64” y queremos traducirlo a un prefijo “externo” diferente que sea visible en la Internet pública, como “2001:db8::/64”. Simplemente debemos configurar NPTv6 según nuestro sistema operativo de red (NOS) para que traduzca un /64 a otro /64. Habremos hecho la traducción sin romper la alcanzabilidad de extremo a extremo de la capa de red y los protocolos L4.
Por lo tanto, en general recomiendo encarecidamente evitar NAT66 para evitar los problemas asociados con este tipo de traducción y usar NPTv6 en todas las redes en producción.
Sin embargo, si nos vemos obligados a usar NAT66, por ejemplo, por ser cliente de DigitalOcean (donde solo proporcionan un /124), lamentablemente perderemos los beneficios de IPv6 (principio de extremo a extremo nativo e independencia del transporte en la Capa 4) y tendremos en la red el mismo problema que el IPv4 con NAT. La única solución sería exigirles que proporcionen IPv6 compatible con las mejores prácticas o cambiarnos a un proveedor que lo haga.
Gestión de bloques PA
Los bloques PA son aquellos que un ISP le asigna a un cliente, en lugar de que el cliente tenga sus propios bloques IPv6 independientes del proveedor (PI). El principal problema con los bloques PA es que debemos numerar cuando cambiamos de proveedor o cuando nuestro proveedor deja de operar o cierra por algún otro motivo.
Uno de los problemas es la renumeración, el otro es el balanceo de carga y la alta disponibilidad cuando tenemos múltiples proveedores con su propio bloque PA único asignado a nuestro negocio. Podríamos usar anuncios de router en IPv6 para anunciar uno u otro bloque según nuestras preferencias, pero esto no permite un verdadero balanceo de carga en la capa de red para emparejar nuestro consumo de ancho de banda.
La única forma de evitar este problema sin usar ULA y sin romper nuestras redes de doble pila es usar NPTv6 en combinación con un espacio de direcciones que no sean ULA. Al momento de escribir este artículo, la IANA no ha asignado un espacio de direcciones dedicado para este fin. En teoría, podemos usar el bloque “200::/7” para nuestra red interna y dividirlo en subredes sobre la base de los lineamientos generales indicados en esta nota.
Sin embargo, debemos tener en cuenta que, dado que el bloque “200::/7” no está asignado oficialmente para uso de NPTv6, permanece en el limbo y en el futuro podría ser reasignado para convertirse quizás en un prefijo para documentación o un prefijo unicast global, con lo cual, en cualquier caso, aún tendremos que renumerar nuestra red interna. En este momento, es el único prefijo que funciona como una alternativa a las ULA para NPTv6, y es de uso “gratuito”.
En resumen, actualmente el IETF no ofrece ninguna solución que sea perfecta con respecto a los problemas operativos de las ULA en las redes en producción.
Es importante tener en cuenta que esta no es una recomendación oficial del IETF, por lo que pueden proceder con mi solución a su propia discreción.
Ejemplo
Supongamos que tenemos dos proveedores, cada uno de los cuales nos dio un /48, y que hemos dividido cada /48 de manera idéntica para que coincidan con nuestra infraestructura de red. También hemos separado dos /48 del bloque “200::/7” que luego dividimos para que coincidiera con el subnetting de nuestro bloque PA.
Supondremos que, por ejemplo, tenemos VLAN1 y VLAN2, para las cuales tenemos dos /64, un conjunto de cada proveedor y otro conjunto de dos /64 del bloque “200::/7”.
Ahora podemos hacer algo en este sentido, en orden de prioridad, tanto para el balanceo de carga como para la alta disponibilidad, teniendo en cuenta que debemos realizar la configuración en ambas direcciones (interna>externa, externa>Internet) para preservar el principio de extremo a extremo.
#Source NPTv6#
200::/64 <NPTv6-translated> ISP1 /64
200:1::/64 <NPTv6-translated> ISP2 /64
#Destination NPTv6#
ISP1 /64 <NPTv6-translated> 200::/64
ISP2 /64 <NPTv6-translated> 200:1::/64A continuación incluimos el ejemplo específico de routerOS v7 usando un solo prefijo de ISP donde “200::/64” es el prefijo interno y “2001:db8::/64” es el bloque PA del ISP.
/ipv6 firewall mangle
add action=snpt chain=postrouting comment="NPTv6 (Internal>External)" dst-prefix=2001:db8::/64 src-address=200::/64 src-prefix=200::/64
add action=dnpt chain=prerouting comment="NPTv6 (External>Internal)" dst-address=2001:db8::/64 dst-prefix=200::/64 src-prefix=2001:db8::/64Seguridad en IPv6
Si bien la seguridad en IPv6 es un tema en sí mismo y, por lo tanto, no es el enfoque de este artículo, considero que de todas maneras es importante mencionar algunos puntos clave para guiar a los lectores en la dirección correcta para que investiguen y prueben la seguridad de IPv6 en su propio entorno de red local.
- No bloquear ciegamente ICMPv6. ICMPv6 ya tiene una tasa limitada por defecto en todos los principales proveedores de redes y sistemas operativos y, por lo tanto, no representa problemas de seguridad adicionales. Sin embargo, podemos bloquear los subtipos de ICMPv6 no válidos u obsoletos según los lineamientos de la IANA. Los mismos principios también se aplican a IPv4.
- Existen algunas preocupaciones con respecto a los ataques de agotamiento del Neighbor Discovery Cache. Sin embargo, siempre que nuestro sistema operativo ya esté limitando la tasa de ICMPv6 y que nos aseguremos religiosamente de enrutar nuestros prefijos a un agujero negro en nuestros routers de borde, routers de acceso, switches L3, etc. (lo que también evita los bucles L3), en la práctica esto no debería plantear ningún problema.
- Podemos limitar nuestra tabla de caché de vecinos a 8k/16k hosts, en cuyo caso realmente no importaría si alguien está escaneando nuestro segmento de VLAN /64, ya que las entradas viejas que son inalcanzables simplemente caducarán y las que son válidas permanecerán en caché. Mi red personal de I+D (AS149794) una vez fue “víctima” de este tipo de ataque, pero incluso en un antiguo MikroTik RB3011, no se vio ningún impacto en el desempeño de la red a pesar de que la tabla de caché de vecinos se inundó hasta el límite de 16k que yo había configurado.
- Esta también es una buena fuente de mejores prácticas de seguridad en IPv6. También existen mejores prácticas de seguridad en IPv6 para MikroTik.
- NAT no es y nunca fue una herramienta de seguridad.
- Para segmentos de red inseguros como VLAN invitadas o VLAN de IoT en una red empresarial, podemos seguir el mismo modelo que los clientes VPN, reglas entrantes en la cadena de forward en el firewall usando iptables (o nftables) para aceptar ICMPv6 establecido, relacionado, sin seguimiento y descartar el resto. Esto garantiza que no haya posibilidad de que actores externos puedan acceder directamente a nuestros hosts desde el exterior, a menos, por supuesto, que nuestro host esté infectado con malware o una red de bots.
- Recomiendo mantener la capa de red simple. Manejar firewalls con estado directamente en el host e implementar control de políticas en el sistema operativo para evitar que los empleados o invitados ejecuten cualquier archivo que posiblemente contenga malware o instalen software no autorizado. Siempre podemos tener un dispositivo de firewall de un tercero que también se encargue de la seguridad, pero personalmente prefiero un enfoque independiente del fabricante. Por lo tanto, mi preferencia personal sería usar firewall en el host usando iptables/nftables o incluso el firewall integrado de Windows, en combinación con un control de políticas en el sistema operativo.
- También podemos implementar filtrado avanzado en los hosts Linux mediante eBPF o XDP si lo que buscamos es un control detallado en empresas de gran escala con el conjunto adecuado de habilidades entre sus empleados.
Conclusión
Voy a enfatizar nuevamente que estos son lineamientos generales y ejemplos. Cada organización puede dividir en subredes de manera diferente, pero siempre debemos asegurarnos de que nuestro backbone y nuestros clientes obtengan subredes suficientes, persistentes (estáticas) y que se puedan escalar en las próximas décadas. BCOP-690 no es una solución mágica para todos los escenarios, pero, junto con este artículo, ofrece lineamientos exhaustivos de un extremo a otro para ayudarnos a lograr un diseño y una arquitectura que cumplan con las mejores prácticas y que se ajusten a nuestras necesidades comerciales y a nuestra red.
Idealmente, se debería evitar el uso de NAT66/NPTv6 tanto como sea posible, ya que ambos frustran el propósito del IPv6 nativo (que solo es posible en una red que cumpla con las mejores prácticas) y solo agrega sobrecarga adicional a la red.
También espero que las Normas Seguridad de Datos de la Industria de Tarjetas de Pago (PCI DSS) aprendan más temprano que tarde que NAT(66) no es una herramienta de seguridad y que no hay necesidad de usar NAT en IPv6, antes de que sus requisitos actuales generen un déficit técnico que se vuelva demasiado difícil de eliminar en el futuro.
Es mi deseo que este artículo cause un impacto en la industria de las redes y que dé lugar a una implementación de IPv6 que cumpla con las mejores prácticas. ¡Espero ver más /48 enrutados!
Agradecería tu apoyo para poder seguir compartiendo contenido valioso sobre ingeniería de redes. Con tu ayuda, podré continuar mis esfuerzos personales y sin fines de lucro. Tu donación me ayudará a realizar valiosos experimentos. Haz clic aquí para donar ahora
Daryll Swer es un entusiasta de la tecnología de la información y las redes (AS149794) a quien lo motiva su pasión por las redes informáticas, especialmente en el mundo del despliegue de IPv6. A través de sus investigaciones en curso e inteligentes contribuciones, ofrece una guía valiosa y ejemplos prácticos para empoderar a los profesionales para que aprovechen todo el potencial de IPv6.
Esta publicación es una adaptación del original publicado en el blog de Daryll.
Las opiniones expresadas por los autores de este blog son propias y no necesariamente reflejan las opiniones de LACNIC.
Considero que es absolutamente inapropiado indicar que los bancos u otras instituciones están exentos de cumplir una norma básica de los estándares del IETF: el uso de NAT66 o NPT66, que son protocolos NO ESTANDARES, sino experimentales, y por lo tanto no sujetos a ser aplicados en ningún entorno de producción. Igualmente, tampoco es una excusa tener que usar espacio PA para el balanceo de carga, lo correcto es recibir del RIR espacio PI (asignaciones directas del RIR, LACNIC en este caso).
En varios países he desplegado IPv6 en entidades bancarias (y otras mas restrictivas) de diferentes tamaños, y nunca he necesitado utilizar NAT en IPv6.
Hello
The translated version of the article may not accurately reflect the message I intended. But regardless, I provided sources from the industry that mentions PCI DSS requires NAT44/NAT66 as the standard was built around the idea of RFC1918 and not all auditors will allow no-NAT IPv6 deployment.
Secondly, whether or not NAT66/NPTv6 are IETF standards, it has not stopped cloud providers such as AWS/GCP/Azure/DigitalOcean etc from either forcing users to use NAT66 (because they only give /124-/128 GUA or similar) or they built their IPv6 infra structure using IPv4 mindset.
Thirdly, I explicitly stated below that I hope PCI DSS get rids of NAT mindset:
https://www.daryllswer.com/ipv6-architecture-and-subnetting-guide-for-network-engineers-and-operators/#:~:text=I%20also%20hope,in%20the%20future.
What the IETF says in the RFCs and what occurs in the ground reality of network deployments (with example given such as the cloud providers), vendor support/behaviour etc are never and rarely if ever 1:1 matching.