The end of IPv4 at Internet Exchange Points: Why IXPs are moving toward IPv6-only and what this means for your AS
June 1, 2026
Projects and development manager @ NIC.br | Driving Internet development in Brazil.
The Paradox of an Internet That Never Ceases to Grow
The Paradox of an Internet That Never Ceases to Grow
IPv4 addresses are exhausted. You already know that. LACNIC, the Regional Internet Registry for Latin America and the Caribbean, exhausted its general pool of IP addresses on 19 August 2020. The same happened at RIPE NCC, the European Regional Internet Registry, in November 2019. Every new IPv4 address obtained today originates from returns, recoveries, or the secondary market, where 2026 surveys estimate the price of a /24 block (256 addresses) at around USD 25 to USD 30 per address.
(Free access, no subscription required)
Despite this, the Internet has continued to grow. Here in Brazil, this growth is driven by IX.br Internet Exchange Points, one of the largest existing IXP networks and home to the world’s largest IXP in terms of traffic volume and number of participating networks, IX.br São Paulo. In March 2026, the IX.br IXP network reached 50 Tbit/s of aggregate traffic, with the initiative present in 39 different metropolitan areas.
There is, however, a problem that is not immediately apparent in this expansion. Even if the traffic passing through an IXP is soon to be predominantly IPv6, internal infrastructure, especially route server sessions, still relies on IPv4 addresses in many scenarios. These addresses come from finite pools, managed with increasing care by the RIRs. There is also a second motivation which is less obvious but operationally very relevant: an IPv6-only peering LAN makes it possible to remove ARP from the IXP’s Ethernet domain. Instead of resolving IPv4 addresses via Ethernet broadcast, neighbor discovery now occurs via Neighbor Discovery in IPv6, using a model that is more controllable and better suited to large-scale shared environments. The solution to this problem already exists, has been standardized, and is already in production at some IXPs. This article explains the problem, the solution, and key considerations for Brazilian operators.
What Is an IXP and Why Internal Addressing Matters
What Is an IXP and Why Internal Addressing Matters
Despite this, the Internet has continued to grow. Here in Brazil, this growth is driven by IX.br Internet Exchange Points, one of the largest existing IXP networks and home to the world’s largest IXP in terms of traffic volume and number of participating networks, IX.br São Paulo. In March 2026, the IX.br IXP network reached 50 Tbit/s of aggregate traffic, with the initiative present in 39 different metropolitan areas.
There is, however, a problem that is not immediately apparent in this expansion. Even if the traffic passing through an IXP is soon to be predominantly IPv6, internal infrastructure, especially route server sessions, still relies on IPv4 addresses in many scenarios. These addresses come from finite pools, managed with increasing care by the RIRs. There is also a second motivation which is less obvious but operationally very relevant: an IPv6-only peering LAN makes it possible to remove ARP from the IXP’s Ethernet domain. Instead of resolving IPv4 addresses via Ethernet broadcast, neighbor discovery now occurs via Neighbor Discovery in IPv6, using a model that is more controllable and better suited to large-scale shared environments. The solution to this problem already exists, has been standardized, and is already in production at some IXPs. This article explains the problem, the solution, and key considerations for Brazilian operators.
What Is an IXP and Why Internal Addressing Matters
What Is an IXP and Why Internal Addressing Matters
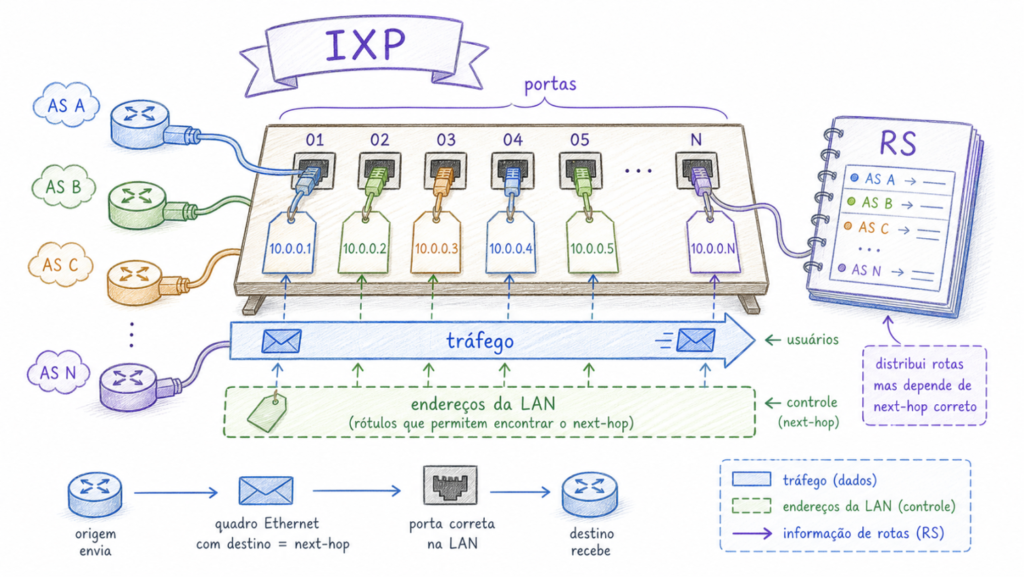
An IXP is, in essence, a large-scale Ethernet network. Hundreds of routers belonging to different organizations (ISPs, content providers, universities, government agencies) connect to a shared switch. From there, each establishes BGP sessions with the others to exchange routing information and, consequently, forward traffic directly, without going through intermediary providers.
To facilitate this process, the IXP operates a Route Server (RS). The route server acts as a central route redistribution agent: instead of each participant establishing BGP sessions with all others individually, each participant establishes only one session with the RS, which redistributes the routes it receives to all others. In an IXP with 500 members, without a route server each participant would need to establish up to 499 bilateral sessions. With the RS, just one is enough. Or two, if there are two route servers for redundancy purposes.
The problem lies precisely in this session with the route server. For it to work with IPv4 routes in traditional mode, the BGP protocol requires that the next-hop address also be an IPv4 address. This means that each participant needs an IPv4 address on the interface connected to the peering LAN, and the IXP needs an IPv4 block to distribute to all its members. Even in a network that already operates almost entirely on IPv6, this dependency persists.
At first glance, this seems inevitable: if there is IPv4 traffic, then the BGP session and the next hop will also have to use IPv4. Right? No, they won’t, and that’s what we’ll explore in detail throughout this article.
But there is another important question that can be asked: for many years, the conventional way of operating route servers at an IXP relied on IPv4 in the peering LAN. This is still true. And it matters because IPv4 is no longer an abundant resource. If ISPs no longer have IPv4 addresses, then how can IX.br and other IXPs continue to be deployed or expand?
RIRs and IXP Addressing: A Protected But Finite Resource
RIRs and IXP Addressing: A Protected But Finite Resource
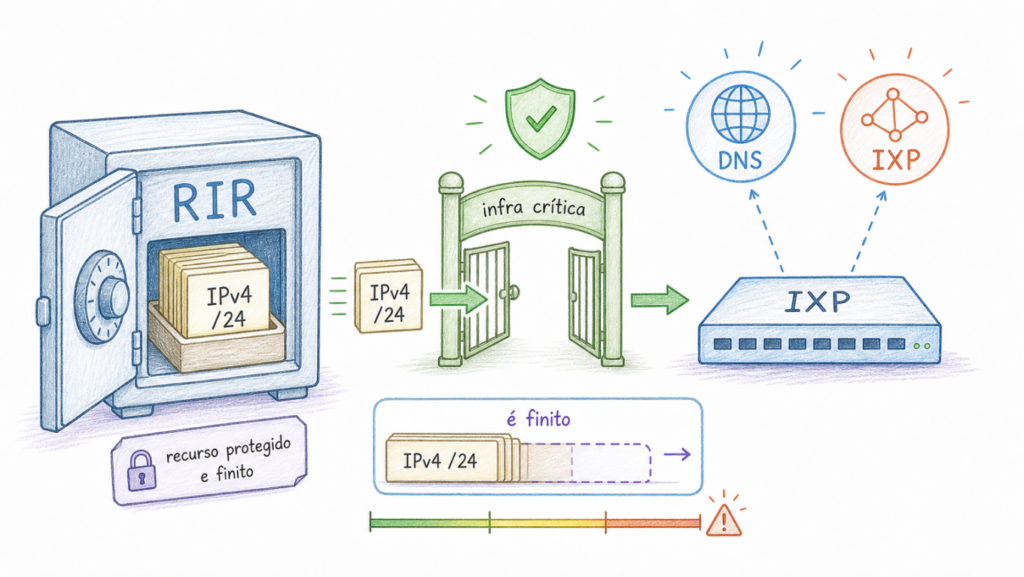
Regional Internet Registries have long recognized that IXPs are vital infrastructure for the Internet. Just as important, for example, as DNS infrastructure and other essential functions. Within the scope of the rules defined by the RIR communities, this is known as critical infrastructure. Each RIR community has created their own special policies to ensure that IPv4 addresses remain available for LAN peering even after the general pool is exhausted.
The RIPE NCC, for example, has reserved a /15 block (131,072 addresses) exclusively for IXPs. The policy is strict: this address space may only be used for the peering LAN, and the IXP is required to return it if it no longer uses it. Even with this safeguard, the RIPE NCC projected that this pool could be exhausted by the second half of 2029. In 2023, it reduced the standard size of initial allocations from /24 to /26 to extend the lifespan of the reserve.
LACNIC takes a different approach but one with a similar intent. Section 2.3.5 of its Policy Manual reserves a /15 block for critical infrastructure, which includes IXPs, RIRs, and ccTLDs. In our region, Phase 3 of IPv4 exhaustion began on 15 February 2017. On 19 August 2020, LACNIC exhausted its pool of available IPv4 addresses and began relying exclusively on recovered or returned resources, in addition to its critical infrastructure reserve. According to public archive critical-infra-latest, as of 9 May 2026, 390 of the 512 /24 blocks that make up this /15 were still reserved, representing 99,840 addresses, or about 76% of the reserve.
There is no immediate crisis. The main argument for the technical change is not urgency, but architecture. Each /24 consumed by an IXP is a block that cannot be assigned to another critical use in the region. The reserve is finite and its consumption is irreversible as long as networks continue to rely on IPv4 for peering, a dependency for which a standardized solution already exists.
The Technical Root of the Problem: How BGP Ties NLRI and Next-Hop to the Same Address Family
The Technical Root of the Problem: How BGP Ties NLRI and Next-Hop to the Same Address Family
Is it possible, then, to use only IPv6 on an IXP’s route server without having a pool of IPv4 addresses for the IXP and still exchange IPv4 prefix information and route traffic normally? The answer is yes. And how to do this is defined and standardized in RFC 8950.
To understand RFC 8950, one must first understand why there was a limitation on advertising IPv4 prefixes with IPv4 next hops. The reason for the limitation was the inner workings of the BGP protocol and deserves a careful explanation.
What BGP Advertises
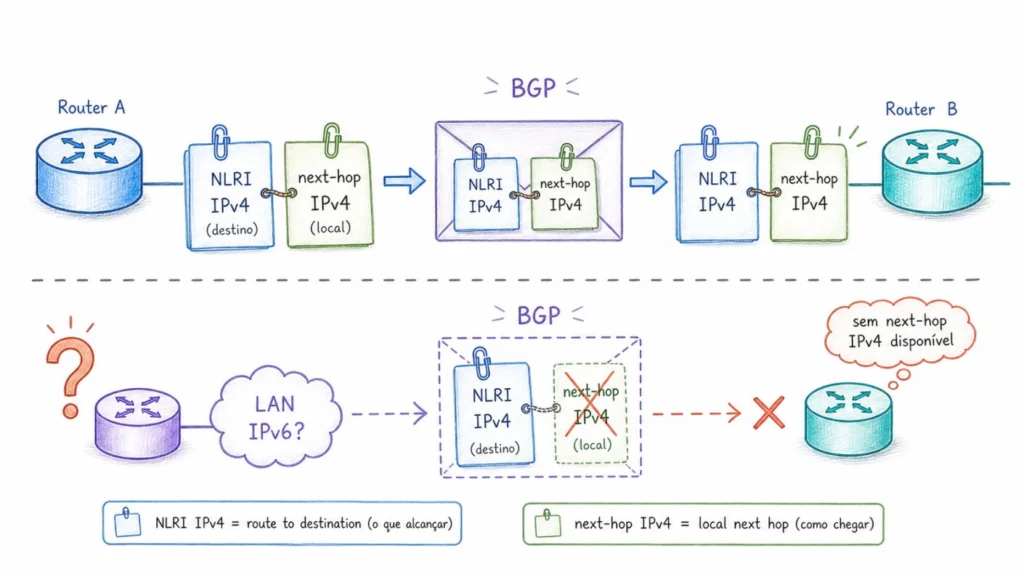
When a router advertises a route via BGP, it essentially sends two pieces of information. The first is the reachable prefix, known as NLRI (Network Layer Reachability Information). The second is the next hop address to reach that prefix.
A good way to visualize this is to think of a collaborative road map. Each participant announces, “The network exists and is reachable by me”. The NLRI is the destination (“Network 200.1.2.0/24 exists”), and the next-hop address is the routing instruction (“To get there, send the packets to 192.0.2.1, which is the address of my interface here at the IXP”). The recipient of the advertisement uses the next-hop address to determine where to send the packets.
This distinction is important: NLRI describes a network that may be dozens of hops away, whereas, in a peering LAN scenario, the next-hop address must be reachable on that local network.
The Address Family and the AFI/SAFI Pair
Multiprotocol BGP (MP-BGP, RFC 4760) extended the protocol to support multiple address families, including IPv4, IPv6, VPNs, MPLS, and others. To identify the family to which each advertisement belongs, a pair of identifiers known as AFI/SAFI is used. AFI (Address Family Identifier) specifies the primary address family: 1 for IPv4 and 2 for IPv6. SAFI (Subsequent Address Family Identifier) specifies the subfamily: 1 for unicast, 2 for multicast, 4 for labeled unicast (MPLS), 128 for VPN, and so on.
When a router receives a BGP update, it examines the AFI/SAFI pair and immediately knows what to expect. An advertisement with AFI=1, SAFI=1 is a standard IPv4 unicast route; one with AFI=2, SAFI=1 is a unicast IPv6 route.
Multiprotocol BGP already allows routers to maintain a single BGP session over IPv6 and advertise IPv4 prefixes over this session, but until now, this was only possible with IPv4 next hops. This is not new; it is simply uncommon. However, that is not what we are talking about here. We are going one step further. We want to advertise a route over a BGP session that was established using IPv6, having (i) an IPv4 NLRI, meaning the destination is an IPv4 prefix, and (ii) an IPv6 next hop.
The Historical Constraint
This is where the problem lies: the original specifications for AFI/SAFI pairs for IPv4 routes (AFI=1) stipulated that the next-hop field must contain an IPv4 address. There was no provision for entering an IPv6 address in this field. The specification was written at a time when IPv6 was an academic project, and no one imagined that one day it would be necessary to advertise IPv4 routes using an IPv6 next hop.
This created a dependency that seems simple but has profound consequences: to advertise IPv4 routes to the route server, a router must have an IPv4 address configured on the peering interface, as this address will be used as the next hop in the advertisements. Without IPv4 on the interface, there is no valid IPv4 next hop, and IPv4 routes cannot be advertised via RS.
So, without RFC 8950, there was no point in standardizing sessions on the route server with IPv6 and advertising the IPv4 prefixes using Multiprotocol BGP over them if the next hop still had to be IPv4. In any case, IPv4 addressing would still be required on the peering network.
The Natural Question: How Does Traffic Get There?
This raises a legitimate question that every operator asks when first encountering the issue. If a router has only IPv6 on its IXP interface, how do IPv4 packets reach it?
The answer is to separate two planes that BGP normally combines: the control plane (where routes are advertised and learned) and the data plane (where packets are actually forwarded).
At the data plane level, an IPv4 packet destined for an IXP participant’s network requires nothing special. It arrives at the IXP switch, the switch delivers it to the correct router using the destination MAC address in the Ethernet frame, and the router processes it as usual. The IPv4 address is in the packet content; all that the Ethernet frame carrying it on the Layer 2 network needs is the correct MAC address.
The problem is in the control plane: how does the router that will forward the packet determine the MAC address of the destination router? With an IPv4 next hop, this process uses ARP. The router sends a broadcast message on the peering LAN asking, “Who has IPv4 address 192.0.2.5?” and the host responds with its MAC address. If there are no IPv4 addresses on the interfaces, there is no way to perform this ARP and no way to determine the destination MAC address.
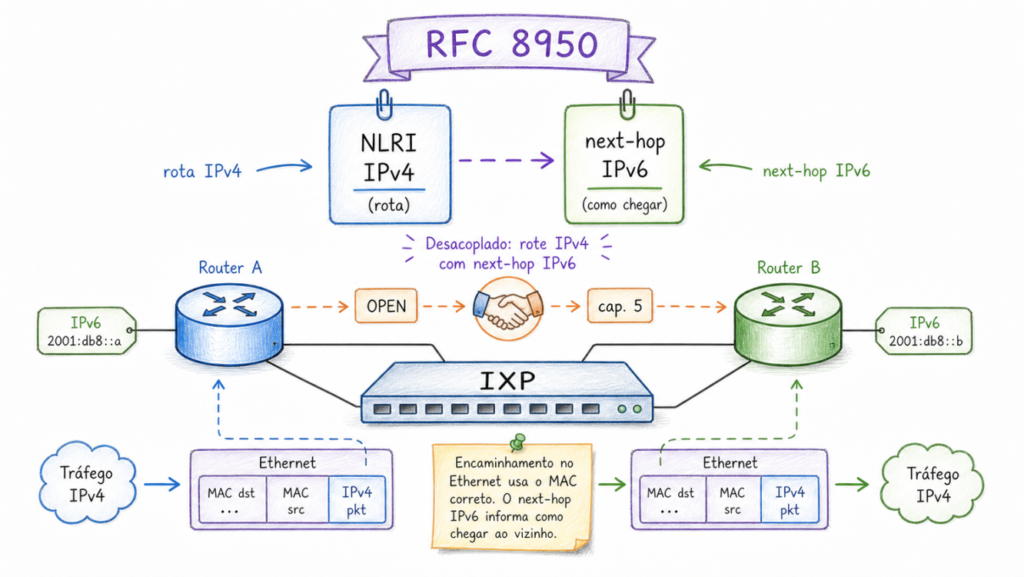
RFC 8950 solves the problem at the control plane level: it allows the router to advertise its IPv4 routes using an IPv6 next hop. The recipient of the advertisement learns that “to reach the 200.1.2.0/24 network, the next hop is IPv6 address 2001:db8::1. To discover the MAC address corresponding to this IPv6 address, Neighbor Discovery (ND) is used, the IPv6 equivalent of ARP. ND works much more efficiently: instead of broadcast, it uses multicast; instead of a separate protocol, it is an integral part of IPv6. The router asks, “Who has IPv6 address 2001:db8::1?” and receives the MAC address in response. From there, IPv4 packets are encapsulated in Ethernet frames destined for the correct MAC address and travel normally through the peering LAN.
To complete the road map analogy: previously, the map said, “To reach network X, go to the yellow gas station on the corner” (a local IPv4 address). With RFC 8950, the map now says, “To reach network X, go to the blue pharmacy on Main Street” (an IPv6 address). Anyone familiar with the neighborhood can get to the pharmacy; the reference was simply provided in a different way, but the traffic reaches its destination just the same. The instruction changed its format, but the functionality remains the same.
The solution: RFC 8950 – Advertising IPv4 Routes with an IPv6 Next Hop
The solution: RFC 8950 – Advertising IPv4 Routes with an IPv6 Next Hop
The idea of separating the NLRI address family from the next-hop address family is not new. Published in 2009, RFC 5549 already proposed exactly that. It already had the right idea, but the market wasn’t ready yet and the specification still had some issues with BGP address families that were important to operators. RFC 8950 did not invent the technique, but rather consolidated and corrected the standard.
Extension of AFI/SAFI Pairs
The first element of RFC 8950 is the extension of the AFI/SAFI definitions. Pairs that describe IPv4 routes (1/1 for unicast, 1/2 for multicast, 1/4 for labeled unicast, 1/128 for VPN-IPv4 unicast, and 1/129 for VPN-IPv4 multicast) now accept an IPv6 next-hop address in the MP_REACH_NLRI field of the BGP message.
The distinction between IPv4 and IPv6 in the next-hop field is determined by the length of the field, but there is an important difference between regular IPv4 unicast and VPN-IPv4. For AFI/SAFI pairs <1/1>, <1/2>, and <1/4>, 4 octets indicate an IPv4 next hop, while 16 or 32 octets indicate an IPv6 next hop (global address, optionally followed by link-local address). For VPN-IPv4 routes (<1/128> and <1/129>), RFC 8950 uses 24 or 48 octets because the next hop is encoded as VPN-IPv6 with an 8-octet Route Distinguisher. The receiving router interprets the next-hop information based solely on the field length, without requiring additional flags.
Negotiation Between Peers: No Surprises, No Disruptions
The second element is the negotiation mechanism. Two routers can only use RFC 8950 if both support RFC 8950 for the given AFI/SAFI pair. To ensure this without disrupting existing sessions, the RFC defines BGP Capability Code 5, known as Extended Next Hop Encoding Capability.
At the start of each BGP session, the two routers exchange OPEN messages. In these messages, each router advertises its capabilities and the protocol extensions it supports. With RFC 8950, a router can advertise, “I am capable of receiving IPv4 unicast NLRI advertisements (AFI=1, SAFI=1) using IPv6 next hops (AFI=2).” If the remote peer also advertises this capability for the same pair, both can use IPv6 next hops for that family. If the remote peer does not advertise this capability, the session should only continue in conventional mode, with IPv4 next hops, if there is still usable IPv4 on the peering LAN or if a translation mechanism is available. In a strictly IPv6-only LAN, a legacy peer will not receive usable IPv4 routes without RFC 8950 support or next-hop translation.
This gradual approach is essential to the adoption strategy in a real-world IXP. The route server can enable RFC 8950 and each member will migrate at their own pace. Members that already support RFC 8950 will begin using IPv6 next hops. Those that do not yet support it will continue to receive IPv4 next hops as long as the environment remains dual-stack or as long as a translation layer for legacy systems exists. The transition will occur peer-to-peer, without requiring a global maintenance window.
Changes in the IXP’s Network
With RFC 8950 fully operational, the IXP can operate the peering LAN without allocating public IPv4 addresses to its members. Each member configures only IPv6 addresses on the peering interface. BGP sessions with the route server use these IPv6 addresses. IPv4 route advertisements carry IPv6 next hops. MAC resolution uses Neighbor Discovery.
In a truly IPv6-only LAN, the benefits are not limited to preserving IPv4 addresses. Perhaps the most relevant operational benefit for the IXP is removing ARP from the peering LAN. ARP is based on broadcasts: every request is sent to all participants on the Ethernet domain, even when only one of them can respond. In large IXPs, this creates constant noise in the Layer 2 control plane and increases the attack surface for issues such as ARP storms, improper responses, spoofing, and the need for specific filtering.
With RFC 8950, next-hop resolution can rely on IPv6 Neighbor Discovery. ND still requires operational controls and should not be assumed to be automatically secure. However, because it uses multicast rather than broadcast, it allows for a more predictable policy: discovery traffic is associated to the IPv6 addressing of the peering LAN, reducing unnecessary exposure to all participants. As a result, the transition to IPv6-only improves not only address management but also the operational hygiene of the IXP’s Ethernet network. In transition scenarios involving legacy peers, however, ARP may continue to exist in a controlled manner, usually through the use of proxying and filtering by the IXP.

MAC Address Operation and Resolution Scenarios
What Does Not Change: User Traffic
It is important to emphasize what RFC 8950 does not change: end-user IPv4 traffic continues to flow normally. RFC 8950 operates exclusively at the BGP control plane, in the exchange of routing information between participating routers. A data packet leaving a server in São Paulo and destined for a user in Recife traverses IX.br exactly as it did before. The IXP switch forwards the packet based on the destination MAC address in the Ethernet frame. The destination router receives the packet and forwards it to its network. None of these operations are affected by RFC 8950.
The change takes place behind the scenes: in how routers learn where each other’s networks are, not in how user packets reach their destination.
Three Years Building the Ecosystem (2023-2026)
Three Years Building the Ecosystem (2023-2026)
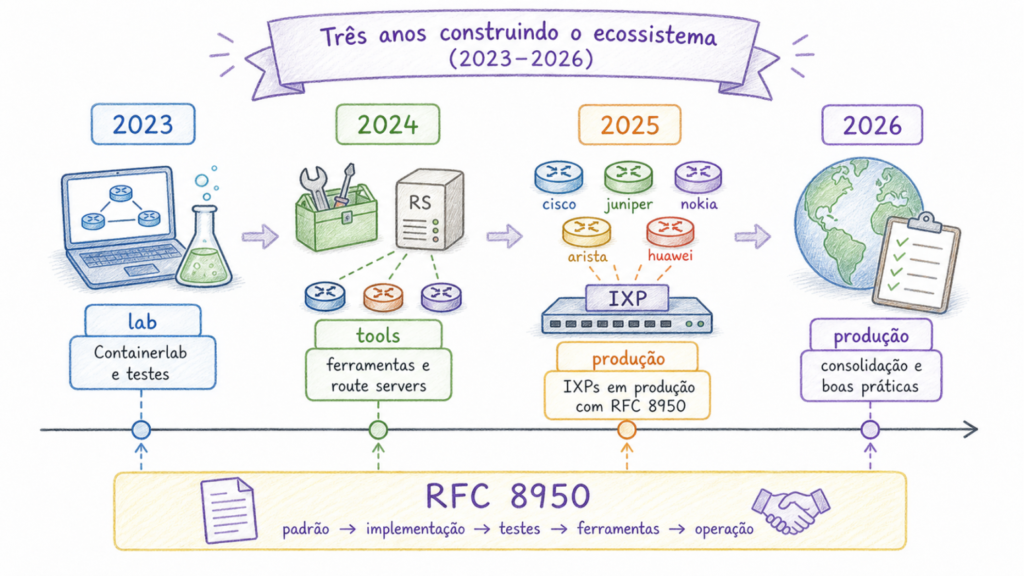
A well-written standard cannot drive an industry on its own. Vendors must implement the solution, operators must test it under real-world conditions, tools such as route servers and looking glasses must be adapted, and the community must produce practical documentation. This work was carried out in a structured and deliberate manner between 2023 and 2026 by an informal working group associated with Euro-IX.
In 2023, the group formalized its charter, defined its objectives, and set up a virtual lab environment using Containerlab, a tool that allows simulating complete network topologies in software. The first vendor-specific tests were distributed among its members. Arista EOS and Juniper Junos worked. Nokia SR-OS required further investigation. ExaBGP lacked documentation for the resource. A pull request with FRR configuration settings was accepted into the repository. A vendor-specific compatibility table was started. In November, an open workshop revealed the complexity of the brownfield environment and stressed the need to support coexistence between peers that support RFC 8950 and those that do not.
In 2024, progress accelerated. ARouteServer incorporated support for RFC 8950 as an official resource. IXP Manager expressed interest in doing the same. An experimental peering environment with RFC 8950 was put into live operation at a European IXP, with actual BGP sessions. Nokia SR-OS began operating in the virtual lab. The impact of RFC 8950 on route server hygiene filters was evaluated and confirmed to be manageable. At the RIPE 88 plenary session, Meta presented its work on removing IPv4 addressing from infrastructure in its edge network, using an IPv6 next hop for IPv4 announcements in parts of the architecture.
In 2025, the world’s first exclusively RFC 8950 IXP began operating in Finland at TREX Turku. Other European IXPs have activated RFC 8950 route servers in production, including BCIX and NIX.CZ/NIX.SK. MikroTik RouterOS 7.20 implemented the resource. Alice-LG now supports BIRD multi-channel BGP and RFC 8950. A multi-vendor interoperability matrix has been published, with test results across multiple vendors and operating systems. IXP Manager has published official configuration templates.
In 2026, the working group concluded their regular meetings and migrated the remaining work to route server discussions, stating that most of the objectives had been met. At the same time, content networks began to treat the technique as an operational requirement: DeepL, for example, states in its PeeringDB that it configures new BGP sessions exclusively over IPv6 for both address families, using BGP Extended Next Hop/RFC 8950.
Current Status: Who Is Already Doing It and What the Numbers Show
Current Status: Who Is Already Doing It and What the Numbers Show
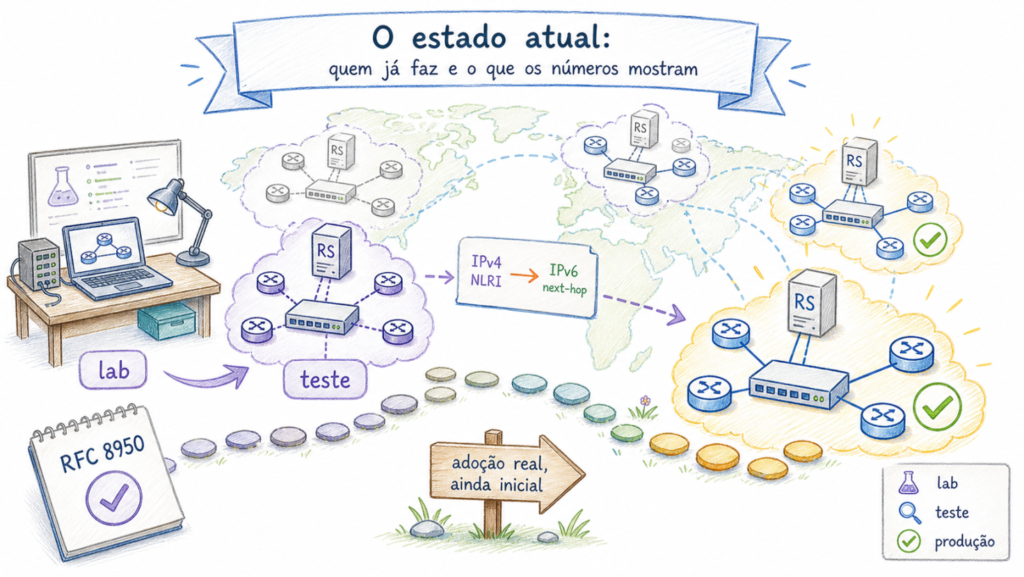
Adoption is still in its early stages, but it is already a reality. According to public materials by the Euro-IX group, documented examples include TREX Turku as RFC 8950-only; TREX Tampere on test route servers; and BCIX, NIX.CZ, and NIX.SK with RFC 8950 route servers in production. At BCIX (Berlin), a presentation reported seven ASNs with RFC 8950 enabled. What is relevant is not the absolute number, as that can change rapidly, but the fact that the technique has moved beyond the lab and is now in operation at actual IXPs.
On the vendor side, support exists across several network operating systems, although the level varies. The table below summarizes the Euro-IX repository survey consulted on 9 May 2026. In production, it is always worth validating the exact version, the address family used, and whether support is limited to RIB or also includes FIB.
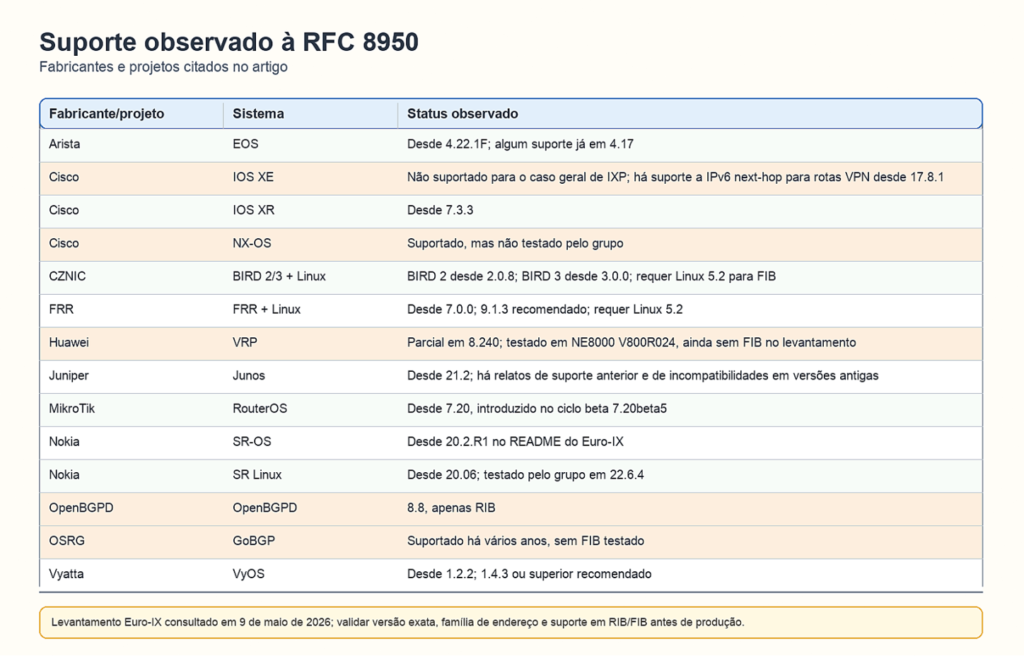
Vendor support.
The Legacy Problem: Not Everyone Supports RFC 8950
The Legacy Problem: Not Everyone Supports RFC 8950
An IXP such as IX.br has hundreds of members operating equipment from different vendors and running different software versions. It is neither reasonable nor operationally feasible to require everyone to migrate at the same time. The transition must be gradual. This means that peers with and without RFC 8950 support will coexist on the same peering LAN for what may be a long period of time.
This is the brownfield scenario, and it is probably the greatest technical challenge for the adoption of RFC 8950 at large IXPs.
The Core Problem of Coexistence
If a route server advertises routes with IPv6 next hops to a peer that does not support RFC 8950, that peer cannot use the routes it receives. It does not know what to do with an IPv6 next hop on an IPv4 route. It may even establish the BGP session, but traffic will not flow.
The most elegant solution is to have the route server itself perform the translation automatically, depending on the peer type. This is what the Internet-Draft by Matějka and Wagner proposes.
IETF Draft on Next Hop Translation
Maria Matějka, a BIRD developer at CZ.NIC, and Daniel Wagner of DE-CIX published individual Internet-Draft “Route Server Next Hop Translation.” Version -01, dated February 27, 2026, is under public discussion at the IETF within the framework of the GROW working group and should be read as a work in progress, not as an approved standard.
The proposal introduces the concept of Specific Local Address Table (SLAT).
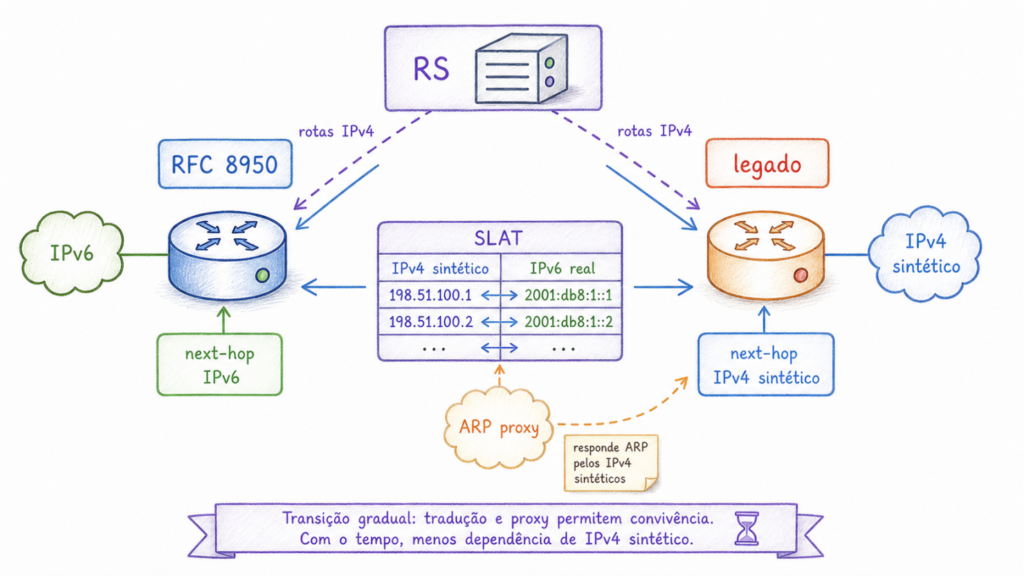
SLAT: One Translation Table per Member
A SLAT is a table maintained by an IXP with one entry per member. Each entry contains the MAC address of the member’s equipment, its IPv6 link-local address, its global IPv6 address, and one or more synthetic IPv4 addresses drawn from blocks reserved strictly for internal use within the IXP interconnection.
A simple way to understand a SLAT is to think of it as a translation table. The route server receives IPv4 route advertisements and internally stores the IPv6 next hop. When it needs to communicate with a legacy participant, it delivers the route with a synthetic IPv4 next hop that the participant can install. Translation is automatic and deterministic, based on the table maintained by the IXP.
The draft defines three types of IXP participants:
- A Legacy Speaker is A participant with no support for RFC 8950. It only understands IPv4 next hops and requires a synthetic IPv4 address in the SLAT to be able to interact with the system.
- A Supporting Speaker supports RFC 8950 but also accepts IPv4 next hops. It can operate in either mode, which makes it useful during transition periods.
- An Unnumbered Speaker supports only RFC 8950 and has no support for IPv4 next hops. It is completely independent of IPv4 addressing on the peering LAN.
How a Route Server Uses the SLAT
The mechanism operates as follows. When a participant announces an IPv4 route to a route server, the RS immediately converts the next hop to the advertiser’s IPv6 address by checking the SLAT. From that point forward, internally, all IPv4 routes have IPv6 next hops.
When announcing a route to an Unnumbered Speaker, the RS sends it with the IPv6 next hop. No additional conversion is required.
When announcing a route to a Legacy Speaker, the RS checks the SLAT and replaces the advertiser’s IPv6 next hop with the corresponding synthetic IPv4 address in the specific column for that Legacy Speaker. The Legacy Speaker receives the route with a local IPv4 next hop and installs it in its routing table as usual.
The ARP Problem and the Proxy Solution
When a Legacy Speaker attempts to forward traffic to this synthetic IPv4 next hop, it issues an ARP request: “Who has address 192.0.2.X?”. To respond to this request, the IXP must have configured an ARP proxy. The proxy intercepts ARP requests from the peering LAN, checks the SLAT to determine which MAC address is associated with which synthetic IPv4 address, and responds on behalf of the owner of that address. The Legacy Speaker receives the response, learns the corresponding MAC address, and forwards the Ethernet frame to the correct destination. For the same reason, the draft also addresses ND proxying and filtering to prevent ARP and ND traffic from simply being forwarded between clients.
From the Legacy Speaker’s perspective, the process is transparent: it sends a normal ARP request and receives a normal response. Behind the scenes, there is a redirection managed by the IXP.
This detail is important: the translation does not change users’ IPv4 packets. It only changes how the legacy router discovers the MAC address associated with the next hop presented by the route server.
IXP Interconnection Space
Synthetic IPv4 addresses must come from somewhere. The draft proposes that IANA allocate an IPv4 /8 from the 240/4 range for use specifically for this purpose, referred to as ‘IXP Interconnection Space.’ Using a standardized IPv4 address block offers two advantages. First, members of different IXPs that use the same block share the same convention, thus reducing the size of SLATs. Second, it avoids conflicts with routable addresses on the public Internet, as these synthetic addresses should never be advertised outside the IXP. As this is an Internet-Draft, this allocation is still a proposal.
Bilateral Peerings: An Important Limitation
The mechanism described above resolves the translation within the context of sessions via a route server. Direct bilateral peerings, where two members establish a BGP session directly with each other without going through the RS, are not automatically resolved by the route server. In these cases, both peers would need to support RFC 8950 directly, maintain IPv4 addresses on the peering interface specifically for those sessions, or implement their own translation based on information published by the IXP.
At large IXPs, the number of bilateral peerings can be high. This limitation is real and needs to be considered when planning. The draft explicitly acknowledges this issue and treats the bilateral case as the responsibility of the participants themselves. However, it suggests that information from the SLAT should be made publicly available to facilitate translations outside the route server.
Will IX.br Be IPv6-Only?
Will IX.br Be IPv6-Only?
IX.br does not currently support RFC 8950 in its route servers and there is currently no timeline for its implementation. There is no immediate urgency as, in the context of LACNIC, the pressure on IPv4 addresses is not cause for concern. There is no formal decision regarding adoption. This article should not be interpreted as an announcement that IX.br plans to adopt IPv6-only route servers. Nevertheless, the direction in which the Internet is heading is clear. IPv6 continues to advance consistently worldwide. The scarcity of IPv4 addresses continues to increase gradually. And the international technical community has demonstrated, through three years of documented testing and results in production, that RFC 8950 is viable at scale.
IX.br’s distributed model, with IXPs operating in 39 metropolitan areas, offers a natural advantage for a potential future gradual transition. It allows testing in a smaller IXP, learning from the experience, adjusting the approach, and expanding to others without affecting the entire ecosystem at once.
What Brazilian ISPs and AS operators can do now is prepare in advance. No rush. No alarm.
The first step is to understand the new standard and become familiar with the concept. That is the purpose of this article. The second step is to take inventory: Which edge routers support RFC 8950? In which operating system versions was support introduced? The compatibility table above provides a good starting point. The next step is testing and bringing this to the lab. Using Containerlab to set up a simulation environment is free and straightforward. A peering LAN with an RFC 8950 route server and several virtual routers can be simulated in just a few hours. Observe how Extended Next Hop capability is negotiated, how the IPv6 next hop appears in routing tables, and how traceroute behaves when there is no IPv4 on the peering interface, all within a lab environment and with no risk to the production network. The euro-ix/rfc8950-ixp repository on GitHub contains examples for Containerlab and vendor-specific configuration guides.
Finally, an important step is to follow the discussions within the IETF, particularly the draft by Matějka and Wagner currently under discussion on the GROW mailing list. Participating in—or at least following—the comments from the international technical community is an effective way to keep track of how the legacy problem is being addressed before it reaches the Brazilian environment.
Conclusion
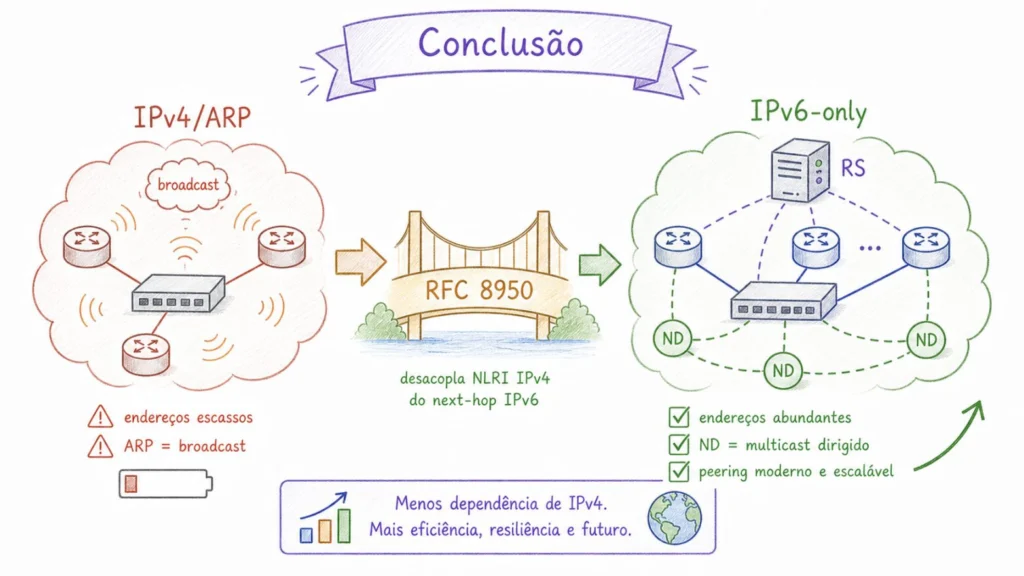
A Technical Evolution That Is Already Underway
The transition of IXPs to IPv6-only route server operation is not a sudden disruption. It is a technical evolution that is already underway, supported by a consolidated standard, mature tools, and proven results in operational IXPs.
RFC 8950 addresses a genuine technical limitation of the BGP protocol: it decouples the NLRI address family from the next-hop family, allows incremental peer-to-peer negotiation, and eliminates the reliance on IPv4 addresses in the peering LAN in scenarios where all relevant participants support the technique. The result is not only the preservation of IPv4 addresses; it is also a cleaner peering LAN, with less reliance on ARP broadcast and neighbor resolution concentrated in the IPv6 plane. The draft by Matějka and Wagner addresses coexistence with legacy peers, enabling a gradual transition in large IXPs, although this is still a work in progress.
In Brazil, the focus right now is on research and preparation. There is currently no pressing operational need to adopt RFC 8950. IX.br has no immediate plans to change, and some vendors widely used across the region still have pending implementation issues. However, the Internet is moving toward IPv6, and those who begin to understand and test RFC 8950 today will be better prepared for the transition than those who don’t start to learn until the need becomes urgent.
The path is well defined, the documentation is available, and Containerlab already allows testing the idea without risk to the production network. Set up a lab, see how it works, and then tell us about your experience.
References
- RFC Editor. RFC 8950: Advertising IPv4 Network Layer Reachability Information (NLRI) with an IPv6 Next Hop, November 2020.
- IETF Datatracker. draft-marenamat-grow-route-server-nh-translation-01: Route Server Next Hop Translation, 27 February 2026.
- Euro-IX. rfc8950-ixp Repository, including README, examples, and presentations.
- Euro-IX mailing list. Concluding the RFC8950-IXP Working Group, March 2026.
- CGI.br/NIC.br. IX.br bate recorde de 50 Tbit/s de tráfego Internet agregado, 20 March 2026.
- LACNIC. Phases of IPv4 Exhausation and Policy Manual, Section 2.3.5.
- LACNIC. critical-infra-latest, a public archive of critical infrastructure reserve statistics.
- RIPE NCC. Policy Proposal 2023-01: Reducing IXP IPv4 Assignment Default Size to a /26, accepted and implemented on 14 September 2023.
- RIPE 88. Removing IPv4 Infrastructure Addressing from Meta’s Edge Network, May 2024.
- IPv4.Center. IPv4 Market Report 2026, March 2026.
- PeeringDB. AS60550 – DeepL SE.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of LACNIC.