Measuring Anycast Prefix Response Times
08/05/2024

By Tomas Lynch, Senior Network Architect at Vultr
How do we know if a prefix we are propagating from different points is considered the best route by other networks? Let’s begin by analyzing what constitutes the best route to a prefix. For me, and I assume for everyone else, it’s the route with the shortest response time and zero packet loss.
If the route is unique, there’s not much we can do — it will be the best even if it is a high-latency route. For a network propagated from a single point, or unicast prefix, there won’t be many options to choose from. However, determining the best route for a prefix propagated from different points, known as anycast networks, can be quite a challenge.
This challenge has existed since the early days of the Internet. The Internet is a topological, not a geographic network. To go from one city to another, packets don’t usually take the shortest physical path, but are routed through a series of interconnections between various networks. Let’s take a look at the following image of an imaginary country called Charlesland.
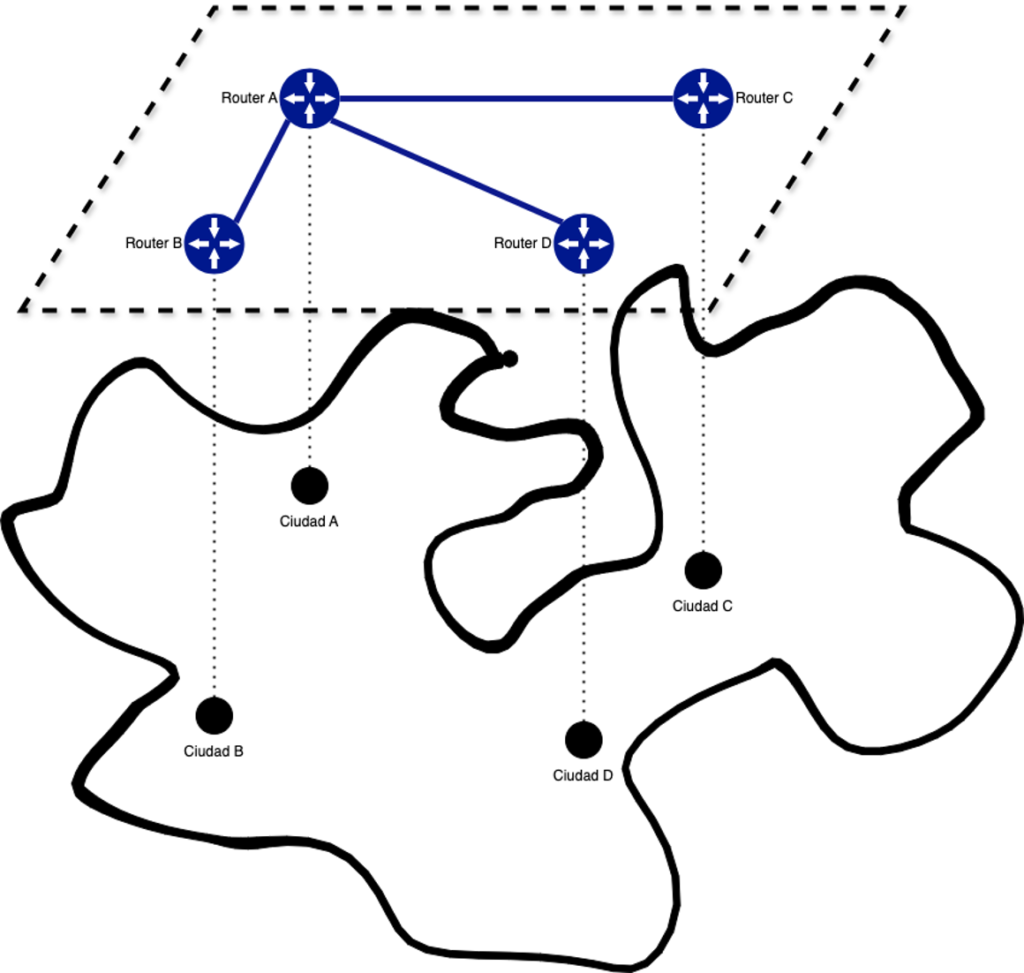
Despite complaints from the residents of City D about response times being twice as long as those in City A, King Charles II of Charlesland decreed that the seat of power would remain in City A, and that all internet links should pass through A. All jokes aside, this situation is quite common within real countries and even more so between different countries, especially when the primary service provider is also a customer of other providers. Considering that networks can use various BGP attributes to decide the best route to an anycast prefix, a network might select the one with the longest response time. This can create latency issues that are difficult to solve without knowing what is going on at the other end.
During LACNIC41, I presented Measuring Anycast Prefix Latency with NLNOG Ring, where I sought to address the problem of sub-optimal routes and understand why they happen, as well as what we can do to influence route selection by third-party networks. To do so, I shared a very useful tool that anyone can use: the Ring de NLNOG project.
How often have we reached out to friends and colleagues asking for a ping from their networks to our prefix to measure latency? How often have we decided not to reach out to them, not wanting to inconvenience them? The idea behind the Ring project is simple: if you allow us to access a physical or virtual machine on your network, we will allow you to access ours.
We will have root access to these machines and will be able to conduct a variety of tests such as ping, mtr, ssh, scp, and more, just as if we were using our own machines. We will also be able to generate simple commands from a group or from all the machines. The following is an example of a ping from 10 Ring member machines to a simulated anycast prefix:
$ ring-ping -n 10 -v -i 2001:db8::1
hostuniversal07: 36.754 [ Australia - AS136557 ]
vultr13: 0.230 [ Mexico - AS20473 ]
isc01: 9.261 [ United States - AS1280 ]
cdw03: 10.451 [ Minnesota, United States - AS3599 ]
kamel01: 1.057 [ Sweden - AS213113 ]
kviknet01: 10.753 [ Denmark - AS204151 ]
grenode01: 9.699 [ France - AS51083 ]
leaseweb02: 0.630 [ Netherlands - AS60781 ]
fnutt01: 8.795 [ Norway - AS57381 ]
inberlin01.ring.nlnog.net: timeout
9 servers: 9.74ms average 9.26ms median
1 unreachable via: inberlin01.ring.nlnog.net
The ring-ping command is used to generate pings from several machines to a specific IP address. In this case, the ping is generated on 10 random servers to 2001:db8::1. Based on our presence in each country, we can tell whether the latency is adequate. For example, if we don’t have presence in Denmark but we do have presence somewhere in Europe, a 10-millisecond latency would be appropriate. Likewise, if we have presence in Australia, depending on the city, those 36 milliseconds could serve as an alarm, prompting us to find out how AS136557 reaches our DNS. This can be done simply by accessing “hostuniversal07” and running an mtr to addresses that are part of our anycast prefixes.
In other words, the Ring project allows us to see how other networks reach the prefixes we propagate to the Internet, thus helping to improve the performance of our network. Additionally, RIPE Atlas tools are installed on all RING nodes, combining the functions of both platforms. More than 500 organizations with autonomous systems in more than 60 countries are currently part of the project.
However, as always, there is a caveat: to date, the participation of machines from the LACNIC region in the project is still very low. Out of the more than 600 machines comprising the Ring project, only 15 are located in our region. This is why I invite you to join this project. All you need to do to gain access to an extremely useful tool with an extensive geographical distribution is to provide a physical or even a virtual machine. To join this project and for more information about the requirements and participants, you can go to https://ring.nlnog.net/.
Click here to watch my full presentation.